单周期mips架构CPU的verilog实现
通过抽象的方式我们从两个方面来构建单周期CPU,也就是数据路径(DataPath)和控制器(Controller)
数据路径
对于一个数据路径,包括取指令(IF),译码(ID),执行(EX),访存(MEM),回写(WB)这几个方面,相应的有IFU,NPC,GRF,ALU,IM,DM这几个基本单元,单元之间通过Splitter和MUX等进行元件之间的数据交换和处理,这里需要在构建是需要留下几个控制信号的接口,以便于最后CU(控制器单元)单元的构建。
IFU取指令单元
该模块由PC(Programming Counter)模块和IM(Instruction Memory)模块组成。其中PC模块负责对每次新的指令状态进行转移,IM模块则从ROM中得到相应的指令。
这里考虑到之后可能需要将IM和DM放到一起,这里不再对PC和IM进行进一步的封装。
PC(程序计数器)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| clk | I | 1 | 时钟信号 |
| reset | I | 1 | 异步复位信号 |
| npc | I | 32 | 通过计算得到的下一条指令的地址 |
| pc | O | 32 | 状态转移后的地址,输出当前正在执行的地址 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 复位 | 当Reset信号有效时,将PC寄存器中的值置为0x00003000 |
| 2 | 停止 | 当Stop信号有效时,PC寄存器忽略时钟输入,PC当前值保持不变 |
| 3 | 写 PC 寄存器 | 当 Stop 信号失效且时钟上升沿来临时,将下一条指令的地址(next PC)写入 PC 寄存器 |
IM(指令存储器)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| pc | I | 32 | 当前正在执行的地址 |
| instr | O | 32 | 输出当前正在执行的指令 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 取指令 | 根据当前PC的值从IM中读出对应的指令 |
NPC(下一指令计算单元)
计算下一个指令,有三种方式,包括直接计算下一条指令,b型跳转指令,j型跳转指令。其中j型跳转指令包括跳转到寄存器的值和直接跳转两种。
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| pc | I | 32 | 当前指令地址 |
| npcOp | I | 2 | NPC控制信号 |
| Imm16 | I | 16 | branch类型的16位立即数 |
| jumpEn | I | 1 | 用于得到branch类型的跳转条件是否成立 |
| imm26 | I | 26 | jump类型的26位立即数 |
| regAddr | I | 32 | 寄存器中存储的地址 |
| PC+4 | O | 32 | 输出PC+4的值 |
| npc | O | 32 | 下一条指令地址 |
| 选择信号类型 | 位宽 | 值 | 描述 |
|---|---|---|---|
| NPC_PC_4 | 2 | 2‘b00 | pc+4 |
| NPC_J | 2 | 2’b01 | 直接跳转,26位立即数拓展后的地址 |
| NPC_B | 2 | 2’b10 | 条件跳转,满足条件跳转到16位立即数拓展后的地址 |
| NPC_JR | 2 | 2’b11 | 跳转到寄存器存储的地址 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
- 三种跳转指令
b型跳转指令

均为判断后跳转到label(即Offset)
JR型跳转指令(jr,jalr)

跳转到寄存器中的存储的地址
J型跳转指令(j,jal)

跳转到target这个立即数对应的地址
其实也可以分为:
间接寻址(通过PC+4和Offset寻址)
直接寻址(直接跳转到立即数对应地址,或者寄存器中存储的地址)
GRF(通用寄存器组)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| CLK | I | 1 | 时钟信号 |
| Reset | I | 1 | 异步复位信号 1:复位信号有效 0:复位信号无效 |
| WE | I | 1 | 写使能信号 1:写入有效 0:写入无效 |
| A1 | I | 5 | 地址输入信号,指定 32 个寄存器中的一个,将其中的数据读出到 RD1 |
| A2 | I | 5 | 地址输入信号,指定 32 个寄存器中的一个,将其中的数据读出到 RD2 |
| A3 | I | 5 | 地址输入信号,指定 32 个寄存器中的一个,将其作为写入目标 |
| WD | I | 32 | 数据输入信号 |
| RD1 | O | 32 | 输出A1指定的寄存器中的 32 位数据 |
| RD2 | O | 32 | 输出A2指定的寄存器中的 32 位数据 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 复位 | Reset 信号有效时,所有寄存器中储存的值均被清零 |
| 2 | 读数据 | 读出 A1,A2 地址对应的寄存器中储存的数据,将其加载到 RD1 和 RD2 |
| 3 | 写数据 | 当 WE 信号有效且时钟上升沿来临时,将 WD 中的数据写入到 A3 地址对应的寄存器 |
EXT(拓展单元)
将16位立即数符号拓展为32位。这里为了提高可拓展性,添加了UnsignedExt接口
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| imm16 | I | 16 | 16位立即数输入信号 |
| extUnsignedSel | I | 1 | 无符号拓展信号 1:无符号拓展(0拓展) 0:符号拓展 |
| imm32 | O | 32 | 32位立即数输出信号 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 符号拓展 | 将16位立即数进行符号拓展 |
ALU(逻辑运算单元)
| ALUOp | 指令 | Opcode | Op |
|---|---|---|---|
| 加法 | add | 0000 | ALURes = SrcA+SrcB |
| 减法 | sub | 0001 | ALURes = SrcA-SrcB |
| 乘法(low) | mul | 0010 | ALURes = SrcA*SrcB |
| 除法(商) | div | 0011 | ALURes = SrcA / SrcB |
| 与运算 | and | 0100 | ALURes = SrcA & SrcB |
| 或运算 | or | 0101 | ALURes = SrcA | SrcB |
| 异或运算 | xor | 0110 | ALURes = SrcA $\oplus$ SrcB |
| 或非运算 | nor | 0111 | ALURes = ~(SrcA | SrcB) |
| 逻辑左移 | sll | 1000 | ALURes = SrcB << Shift |
| 逻辑右移 | srl | 1001 | ALURes = SrcB >> Shift |
| 算数右移 | sra | 1010 | ALURes = SrcB >>> Shift |
DM(数据存储器)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| clk | I | 1 | 时钟信号 |
| reset | I | 1 | 复位信号 |
| addr | I | 32 | 内存中的地址信号 |
| dmOp | I | 2 | 选择信号 2’b00:word 2’b01:half_word 2’b10:byte |
| dmWriteEn | I | 1 | 写使能信号 1:写入有效 0:写入无效 |
| WD | I | 32 | 在写入信号有效时,写入内存地址的数据 |
| RD | O | 32 | 输出内存中对应地址的数据 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
Splitter
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| instr | I | 32 | 输入指令信号 |
| opcode | O | 6 | instr[31:26] |
| rs | O | 5 | instr[25:21] |
| base | O | 5 | instr[25:21] |
| rt | O | 5 | instr[20:16] |
| rd | O | 5 | instr[15:11] |
| sa | O | 5 | instr[10:6] |
| func | O | 6 | instr[5:0] |
| imm26 | O | 26 | instr[25:0] |
| imm16 | O | 16 | instr[15:0] |
CMP
用于生成Branch类跳转信号是否跳转的使能信号
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| cmpA | I | 32 | 输入信号 |
| cmpB | I | 32 | 输入信号 |
| branchOp | I | 比较类型 | |
| jumpOp | O | 1 | 是否满足跳转条件 |
- 功能定义
| branchOP | 值 | ||
|---|---|---|---|
控制
CU
| 指令 | Opcode[31:26] | [25:21] | [20:16] | [15:11] | [10:6] | [5:0 |
|---|---|---|---|---|---|---|
| add | 000000 | rs | rt | rd | 00000 | 100000 |
| sub | 000000 | rs | rt | rd | 00000 | 100010 |
| ori | 001101 | rs | rt | immediate | ~ | ~ |
| lw | 100011 | base | rt | offset | ~ | ~ |
| sw | 101011 | base | rt | offset | ~ | ~ |
| beq | 000100 | rs | rt | offset | ~ | ~ |
| lui | 001111 | 00000 | rt | immediate | ~ | ~ |
| nop | 000000 | 0 | 0 | 0 | 0 | 0 |
由于我是先搓完的数据路径部分,在写到CU的时候对于大多数的接口已经不记得了。这里可以学习黑书中的模式,通过一条指令来构建起其中的一些指令的控制,然后加指令来增加前面可能缺少的接口,同时补全接口的定义等。
首先我是将一些和初始化、终止等相关的接口拿出来,这些基本上是自定义的,用于提高CPU的可拓展性。比如在IFU中的Stop,EXT中的UnsignedExt信号等。
其次从CU的角度开始处理指令。
第一步,输入信号。
这里包括两个,Instr[31:26]也就是Opcode,Instr[5:0]也就是在R类型指令中的Func。
对这两个进行输入解析。利用And Logical,判断得到对应什么指令。
然后利用Or Logical,来激活相应的接口。
第二步,对于lw指令。
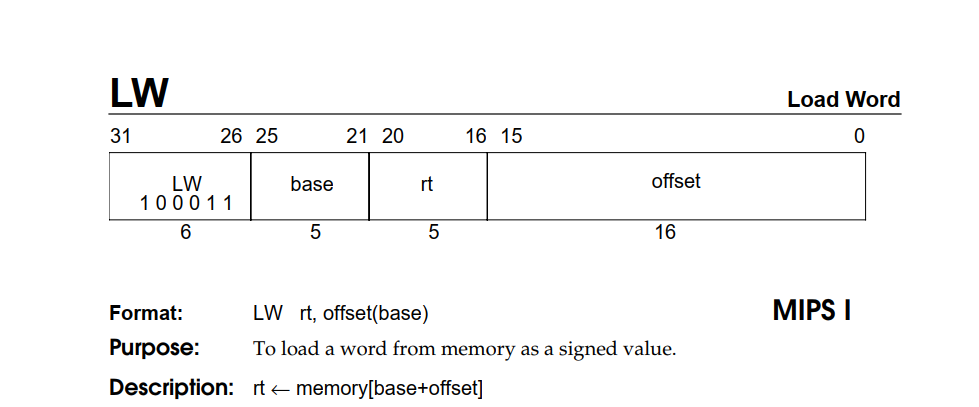
这里首先调整了几个选择信号,同时检查发现加上了WriteReg控制信号。
第三步,对于sw信号。
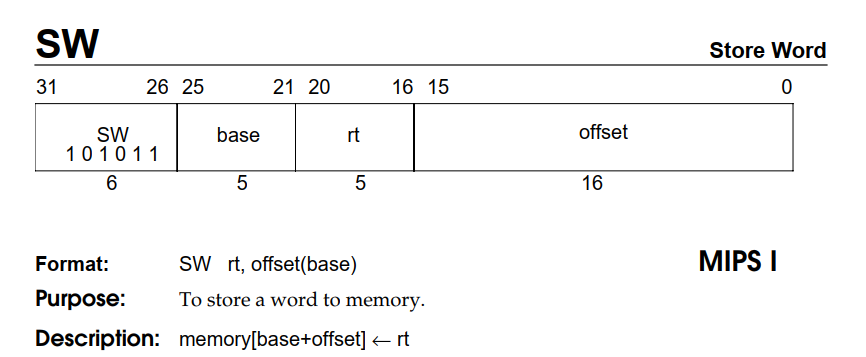
发现sw和lw基本一模一样。做完这两个之后对于整体指令已经熟悉了,然后开始实现剩余的指令控制信号。
最后,反过来从接口的角度思考有哪些指令需要用到该接口或者对该接口有什么操作,然后对CU进行补全以及检查。
自动化测试
思考题
- 阅读下面给出的 DM 的输入示例中(示例 DM 容量为 4KB,即 32bit × 1024 字),根据你的理解回答,这个 addr 信号又是从哪里来的?地址信号 addr 位数为什么是 [11:2] 而不是 [9:0] ?

addr信号来自于ALU。因为是按字存储的,每四个byte一个字节。
- 思考上述两种控制器设计的译码方式,给出代码示例,并尝试对比各方式的优劣。
记录指令的控制信号如何取值
always @(*) begin if(opcode == 0) begin case(func) 6'b100000 : begin npcOp == `NPC_PC_4; writeRegSel == `CU_GRF_A3_RD; grfWriteEn == 1'b1; end endcase end else begin case (opcode): `CU_add_OP : begin end endcase end end记录控制信号每种取值所对应的指令
assign npcOp = (beq) ? `NPC_B : (j | jal) ? `NPC_J : (jr) ? `NPC_JR: `NPC_PC_4; assign writeRegSel = (add | sub | sll) ? `CU_GRF_A3_RD : (ori | lw | sw | lui ) ? `CU_GRF_A3_RT : (jal) ? `CU_GRF_A3_RA : `CU_GRF_A3_RD ; assign grfWriteEn = (add | sub | ori | lui | sll | jal | lw) ? 1'b1 : 1'b0; assign writeRegDataSel = (add | sub | ori | lui | sll) ? `CU_GRF_WD_ALURESULT : (lw) ? `CU_GRF_WD_MEMRD : (jal) ? `CU_GRF_WD_PC_4 : `CU_GRF_WD_ALURESULT; assign extUnsignedSel = (ori | lui) ? 1'b1 : 1'b0; assign aluSrcSel = (add | sub | beq | sll) ? `CU_ALU_SRCB_GRFRD2 : (ori | lui | lw | sw) ? `CU_ALU_SRCB_IMM32 : `CU_ALU_SRCB_GRFRD2 ; assign shamtSel = (lui) ? `CU_ALU_SHAMT_SEL_16 : (sll) ? `CU_ALU_SHAMT_SEL_sa : `CU_ALU_SHAMT_SEL_sa; assign aluOp = (add | lw | sw) ? `ALU_add : (sub) ? `ALU_sub : (ori) ? `ALU_or : (lui | sll) ? `ALU_sll : `ALU_add; assign dmWriteEn = (sw) ? 1'b1 : 1'b0; assign dmOp = (lw | sw) ? `DM_WORD : `DM_WORD ; assign branchOp = (beq) ? `CMP_EQUAL : (bne) ? `CMP_NOT_EQUAL : (bge) ? `CMP_SIGNED_GREATER_OR_EQUAL : (ble) ? `CMP_SIGNED_LESS_OR_EQUAL : (blt) ? `CMP_SIGNED_LESS : (bgt) ? `CMP_SIGNED_GREATER : `CMP_EQUAL;
- 记录指令的控制信号如何取值,更加方便记录追踪每一条指令的问题。这个对于增加指令也比较方便。
- 记录控制信号每种取值所对应的指令,方便看某一个控制指令的组成
- 在相应的部件中,复位信号的设计都是同步复位,这与 P3 中的设计要求不同。请对比同步复位与异步复位这两种方式的 reset 信号与 clk 信号优先级的关系。
同步复位中,clk信号优先于reset信号。
异步复位中,reset信号优先于clk信号。
- C 语言是一种弱类型程序设计语言。C 语言中不对计算结果溢出进行处理,这意味着 C 语言要求程序员必须很清楚计算结果是否会导致溢出。因此,如果仅仅支持 C 语言,MIPS 指令的所有计算指令均可以忽略溢出。 请说明为什么在忽略溢出的前提下,addi 与 addiu 是等价的,add 与 addu 是等价的。提示:阅读《MIPS32® Architecture For Programmers Volume II: The MIPS32® Instruction Set》中相关指令的 Operation 部分。
addi和addiu的区别,add和addu的区别在于addi和add在溢出是会报溢出异常,忽略溢出二者自然就相同了嘛。
add
addu
addi
addiu




命名的合理性
元件统一大驼峰(首字母大写)
接口连线统一小驼峰(首字母小写),单个字母仍然使用大写以保证美观。(想了想GRF还是采用以前的A1这种命名吧,不然感觉好奇怪。
操作控制:选择信号以Op结尾
写使能控制:使能信号以En结尾
多路控制:多路选择器开关信号以Sel结尾。

