$\mathscr {Hugo}$ $\mathbb{CPU}$ 五级流水线$\mathscr{Design}$
这里是hugo的blog
P6-P7
MIPS微系统
有亿点点麻烦,首先阐释具体的概念,然后是工程化的应用。
- P7的任务是实现一个简单的计算机系统,即“mips微系统”
- 为了实现CPU的异常报告和与外设进行复杂的交互
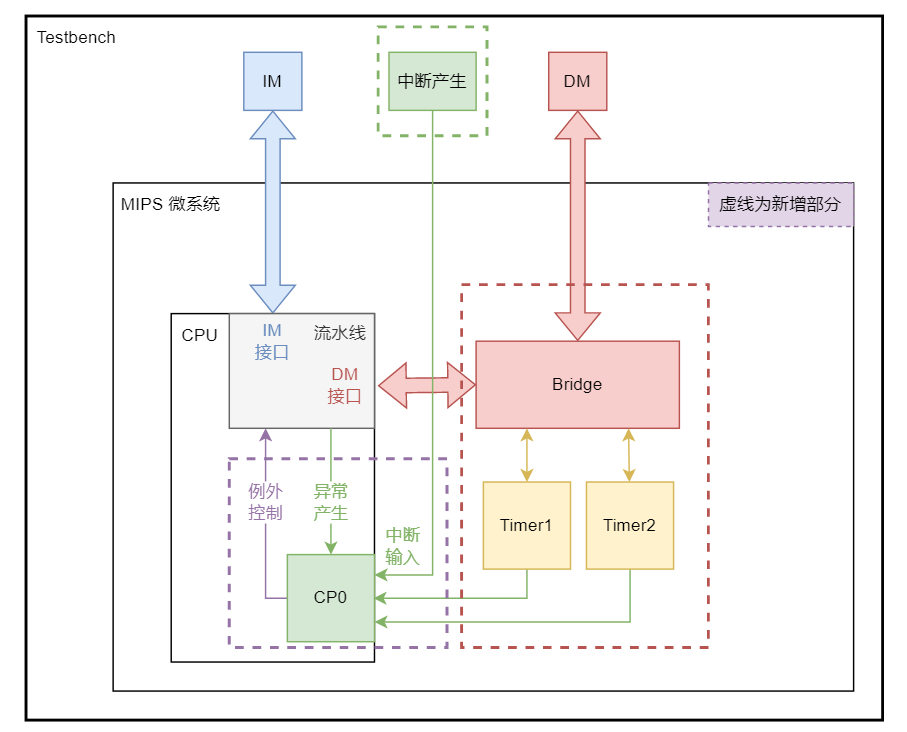
外设
暂时不重要
- Timer
- Memory
- InterruptGenerator
Timer那里的是定时产生时钟中断。
InterruptGenerator是产生随机的外部中断信号,用来模拟外界情形

Q:我们计组课程一本参考书目标题中有 “硬件 / 软件接口” 接口字样,那么到底什么是 “硬件 / 软件接口”?(Tips:什么是接口?和我们到现在为止所学的有什么联系?)
A: 硬件 / 软件接口是指软件和硬件之间数据交互的接口。在我看来,这个应该指的是操作系统,操作系统将外部软件程序的机器码传入 core,由 core 执行;而 core 执行后产生的数据又通过操作系统传给软件。
Q:BE 部件对所有的外设都是必要的吗?
A: 我认为没有必要,BE 部件是为了实现 DM 按字节访存设置的,而其他的部件例如 Timer 仅仅支持按字访存,因此不需要 BE 部件。
Q:请查阅相关资料,说明鼠标和键盘的输入信号是如何被 CPU 知晓的?
A: 鼠标和键盘等外设并不是直接与 CPU 相连的,中间需要通过软件来连接,这个软件也就是我们熟知的驱动。驱动和硬件之间通过操作系统进行处理。
Q: 请开发一个主程序以及定时器的 exception handler。整个系统完成如下功能:
(1)定时器在主程序中被初始化为模式 0;
(2)定时器倒计数至 0 产生中断;
(3)handler 设置使能 Enable 为 1 从而再次启动定时器的计数器。(2) 及 (3) 被无限重复。
(4)主程序在初始化时将定时器初始化为模式 0,设定初值寄存器的初值为某个值,如 100 或 1000。(注意,主程序可能需要涉及对 CP0.SR 的编程,推荐阅读过后文后再进行。)
A:
verilog
主程序: .text ori $t0, $0, 0xfc01 mtc0 $t0, $12 ori $t0, $0, 0x0 sw $t0, 0x7f00 ori $t0, $0, 288 sw $t0, 0x7f04 ori $t0, $0, 0x9 sw $t0, 0x7f00 addi $t1, $0, 1 loop: add $s0, $0, $0 add $s1, $0, $0 add $s2, $0, $0 add $s3, $0, $0 j loop 异常处理程序: .ktext 0x00004180 ori $k0, $0, 0x1 ori $k1, $0, 0x9 sw $k0, 0x7f00 sw $k1, 0x7f00 eret
P5-P6
本次迭代新增了不少calc_r,calc_i型指令,这类指令基本上不敲错code基本上没啥问题,对于新增的md,mt,mf类型的指令,新增一个D_MDU进行处理。
关键这里将IM和DM进行了外置
实现五级流水线CPU
- 命名统一采用hugo命名法(借鉴了匈牙利命名法和下划线命名)
- 主体为mips.v模块,不再像P4一样加入DataPath模块,统一在mips.v中完成连线等大部分操作。
- 控制部分分为
Ctrl_Unit和Hazard_Ctrl两个部分,处理冲突为在能够使用旁路转换的情况下尽可能的使用旁路转换 - 流水线阶段分为IF,ID,EX,MEM,WB五个部分
- F:
NPC,PC,IM - D:
GRF,EXT,CMP - E:
ALU - M:
DM - W:
GRF
- F:
- 其中用到大部分的宏定义在
def.v中定义
CPU流水线的实现
实现指令说明
将本CPU实现的指令分为以下几类:
| classify | 指令set |
|---|---|
| load | lw//lh,lhu,lb,lbu |
| store | sw//sh,sb |
| calc_r | add,sub//addu, subu,and,or,nor,xor,slt,sltu |
| calc_i | ori//addiu,addi,xori,slti,sltiu |
| shift_s | sll//sra,srl |
| shift_v | //sllv,srav,srlv |
| b_type | beq//bne |
| j | jal,j |
| 特殊 | jr,lui |
基本的数据通路
IF阶段的pc需要保留到后面继续使用
重点处理的在于ALU
命名规范
- 对于每一个模块依旧采用仅有文件英文名的办法,对于其实例化为_小写
- 对于每一条线采用层级+命名的方式(原本采用的是匈牙利命名法,也就是前面加上对应的类型,后发现全部都是wire,遂弃之)
- 寄存器文件采用两边的流水线层级加上_REG的方式。
数据通路DataPath
同P4,变量命名有稍微修改。
但没有单独使用一个DataPath的模块,显得比较多余。
对于一个数据路径,包括取指令(IF),译码(ID),执行(EX),访存(MEM),回写(WB)这几个方面,相应的有IFU,NPC,GRF,ALU,IM,DM这几个基本单元,单元之间通过Splitter和MUX等进行元件之间的数据交换和处理,这里需要在构建是需要留下几个控制信号的接口,以便于最后CU(控制器单元)单元的构建。
IFU取指令单元
该模块由PC(Programming Counter)模块和IM(Instruction Memory)模块组成。其中PC模块负责对每次新的指令状态进行转移,IM模块则从ROM中得到相应的指令。
这里考虑到之后可能需要将IM和DM放到一起,这里不再对PC和IM进行进一步的封装。
F_PC(程序计数器)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_clk | I | 1 | 时钟信号 |
| i_reset | I | 1 | 异步复位信号 |
| i_en | I | 1 | 使能信号 |
| i_npc | I | 32 | 通过计算得到的下一条指令的地址 |
| or_pc | O | 32 | 状态转移后的地址,输出当前正在执行的地址 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 复位 | 当Reset信号有效时,将PC寄存器中的值置为0x00003000 |
| 2 | 停止 | 当Stop信号有效时,PC寄存器忽略时钟输入,PC当前值保持不变 |
| 3 | 写 PC 寄存器 | 当 Stop 信号失效且时钟上升沿来临时,将下一条指令的地址(next PC)写入 PC 寄存器 |
F_IM(指令存储器)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_pc | I | 32 | 当前正在执行的地址 |
| o_instr | O | 32 | 输出当前正在执行的指令 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 取指令 | 根据当前PC的值从IM中读出对应的指令 |
D_NPC(下一指令计算单元)
计算下一个指令,有三种方式,包括直接计算下一条指令,b型跳转指令,j型跳转指令。其中j型跳转指令包括跳转到寄存器的值和直接跳转两种。
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_pc | I | 32 | 当前指令地址 |
| i_npcOp | I | 2 | NPC控制信号 |
| i_imm16 | I | 16 | branch类型的16位立即数 |
| i_imm26 | I | 26 | jump类型的26位立即数 |
| i_jumpEn | I | 1 | 用于得到branch类型的跳转条件是否成立 |
| i_ra_of_jr | I | 32 | 寄存器中存储的地址 |
| o_npc | O | 32 | 下一条指令地址 |
| 选择信号类型 | 位宽 | 值 | 描述 |
|---|---|---|---|
| NPC_PC4 | 3 | 3‘b000 | pc+4 |
| NPC_J | 3 | 3’b001 | 直接跳转,26位立即数拓展后的地址 |
| NPC_B | 3 | 3’b010 | 条件跳转,满足条件跳转到16位立即数拓展后的地址 |
| NPC_JR | 3 | 3’b011 | 跳转到寄存器存储的地址 |
- 三种跳转指令
b型跳转指令

均为判断后跳转到label(即Offset)
JR型跳转指令(jr,jalr)

跳转到寄存器中的存储的地址
J型跳转指令(j,jal)

跳转到target这个立即数对应的地址
其实也可以分为:
间接寻址(通过PC+4和Offset寻址)
直接寻址(直接跳转到立即数对应地址,或者寄存器中存储的地址)
D_GRF(通用寄存器组)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_clk | I | 1 | 时钟信号 |
| i_reset | I | 1 | 异步复位信号 1:复位信号有效 0:复位信号无效 |
| i_writeEn | I | 1 | 写使能信号 1:写入有效 0:写入无效 |
| i_A1 | I | 5 | 地址输入信号,指定 32 个寄存器中的一个,将其中的数据读出到 RD1 |
| i_A2 | I | 5 | 地址输入信号,指定 32 个寄存器中的一个,将其中的数据读出到 RD2 |
| i_A3 | I | 5 | 地址输入信号,指定 32 个寄存器中的一个,将其作为写入目标 |
| i_WD | I | 32 | 数据输入信号 |
| o_RD1 | O | 32 | 输出A1指定的寄存器中的 32 位数据 |
| o_RD2 | O | 32 | 输出A2指定的寄存器中的 32 位数据 |
| i_pc | I | 32 | 用于$display |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 复位 | Reset 信号有效时,所有寄存器中储存的值均被清零 |
| 2 | 读数据 | 读出 A1,A2 地址对应的寄存器中储存的数据,将其加载到 RD1 和 RD2 |
| 3 | 写数据 | 当 WE 信号有效且时钟上升沿来临时,将 WD 中的数据写入到 A3 地址对应的寄存器 |
D_EXT(拓展单元)
将16位立即数符号拓展为32位。这里为了提高可拓展性,添加了UnsignedExt接口
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_imm16 | I | 16 | 16位立即数输入信号 |
| i_unsigned_ext_Sel | I | 1 | 无符号拓展信号 1:无符号拓展(0拓展) 0:符号拓展 |
| o_imm32 | O | 32 | 32位立即数输出信号 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 符号拓展 | 将16位立即数进行符号拓展 |
D_CMP(B类指令比较单元)
用于生成Branch类跳转信号是否跳转的使能信号。该单元根据输入的branchOp信号对当前B指令的类型进行判断,进而对当前输入的数值进行比较,最后输出结果。
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_cmpA | I | 32 | 输入信号 |
| i_cmpB | I | 32 | 输入信号 |
| i_branchOp | I | 比较类型 | |
| jumpOp | O | 1 | 是否满足跳转条件 |
- 功能定义
| branchOP | 位宽 | 值 | 描述 |
|---|---|---|---|
| CMP_EQUAL | 4 | 4‘b0000 | 判断是否相等 |
E_ALU(逻辑运算单元)
该模块可实现加,减,按位与,按位或等 11 种运算,并根据 ALUOP 信号的值在这些功能中进行选择。除此之外,该模块还可以实现溢出判断
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| ALUOp | I | 4 | ALU 功能选择信号 |
| src_A | I | 32 | 参与 ALU 计算的第一个值 |
| src_B | I | 32 | 参与 ALU 计算的第二个值 S |
| shamt | I | 5 | 移位数输入 |
| out | O | 32 | 输出 ALU 计算结果 |
- 功能定义
| ALUOp | 指令 | Opcode | Op |
|---|---|---|---|
| 加法 | add | 00000 | ALURes = SrcA+SrcB |
| 减法 | sub | 00001 | ALURes = SrcA-SrcB |
| 乘法(low) | mul | 00010 | ALURes = SrcA*SrcB |
| 除法(商) | div | 00011 | ALURes = SrcA / SrcB |
| 与运算 | and | 00100 | ALURes = SrcA & SrcB |
| 或运算 | or | 00101 | ALURes = SrcA | SrcB |
| 异或运算 | xor | 00110 | ALURes = SrcA $\oplus$ SrcB |
| 或非运算 | nor | 00111 | ALURes = ~(SrcA | SrcB) |
| 逻辑左移 | sll | 01000 | ALURes = SrcB << Shift |
| 逻辑右移 | srl | 01001 | ALURes = SrcB >> Shift |
| 算数右移 | sra | 01010 | ALURes = SrcB >>> Shift |
M_DM(数据存储器)
- 端口定义
| 信号名 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| i_clk | I | 1 | 时钟信号 |
| i_reset | I | 1 | 复位信号 |
| i_Addr | I | 32 | 内存中的地址信号 |
| i_dmOp | I | 2 | 选择信号 2’b00:word 2’b01:half_word 2’b10:byte |
| i_WriteEn | I | 1 | 写使能信号 1:写入有效 0:写入无效 |
| i_writeData | I | 32 | 在写入信号有效时,写入内存地址的数据 |
| o_RD | O | 32 | 输出内存中对应地址的数据 |
- 功能定义
| 序号 | 功能名称 | 功能描述 |
|---|---|---|
| 1 | 复位 | reset信号有效时,所有寄存器的中存储的值均被清零 |
| 2 | 读数据 | 读出A地址对应的存储单元的数据,将其加载到RD |
| 3 | 写数据 | 当WE信号有效且时钟上升沿来临时,将WD中的数据写入到A地址对应的存储单元 |
流水器寄存器模块定义
采用的是分布式译码,流水的是pc和instr,在每个阶段实例化CU模块,得到该阶段的对应控制信号。
FD_REF(IF/ID流水寄存器)
-
端口定义
方向 信号名 位宽 描述 输入来源 I i_clk 1 时钟信号 mips.v 中的 clk I i_reset 1 同步复位信号 mips.v 中的 reset I i_en 1 D 级寄存器使能信号 HCU 中 stall 信号取反 I i_flush 1 D 级寄存器清空信号 默认为 1‘b0 I F_instr 32 F 级 instr 输入 IFU_instr I F_pc 32 F 级 pc 输入 IFU_pc O D_instr 32 D 级 instr 输出 O D_pc 32 D 级 pc 输出
DE_Reg(ID/EX 流水寄存器)
-
端口定义
方向 信号名 位宽 描述 输入来源 I i_clk 1 时钟信号 mips.v中的clk I i_reset 1 同步复位信号 mips.v中的reset I i_en 1 使能信号 from HU I i_flush 1 清空信号 from HU I i_pc 32 I i_instr 32 O or_pc 32 O or_instr 32 I i_grf_RD1 32 D级产生的有效信号 from GRF I i_grf_RD2 32 D级产生的有效信号 from GRF I i_ext_result 32 D级产生的有效信号 from EXT O or_grf_RD1 32 传给E级的有效信号 O or_grf_RD2 32 传给E级的有效信号 O or_ext_result 32 传给E级的有效信号 -
运算功能
$Tnew_D = (Tnew_E > 0) ? (Tnew_D-1) : 0$
EM_Reg(EX/MEM 流水寄存器)
-
端口定义
方向 信号名 位宽 描述 输入来源 I i_clk 1 时钟信号 mips.v中的clk I i_reset 1 同步复位信号 mips.v中的reset I i_en 1 使能信号 from HU I i_flush 1 清空信号 from HU I i_pc 32 I i_instr 32 O or_pc 32 O or_instr 32 I i_alu_result 32 I i_mem_writeData 32 关于sw的来自GRF_RD2的信号 I i_ext_result 32 O or_alu_result 32 O or_mem_writeData 32 O or_ext_result 32 -
运算功能
我这里暂停部分在专门的一个模块HU中解决了
$Tnew_E = (Tnew_D > 0) ? (Tnew_E-1) : 0$
MW_Reg(MEM/WB 流水寄存器)
-
接口定义
方向 信号名 位宽 描述 输入来源 I i_clk 1 时钟信号 mips.v中的clk I i_reset 1 同步复位信号 mips.v中的reset I i_en 1 使能信号 from HU I i_flush 1 清空信号 from HU I i_pc 32 I i_instr 32 O or_pc 32 O or_instr 32 I i_dm_RD 32 来自dm的数据读出信号 from M_DM I i_alu_result 32 I i_ext_result 32 O or_dm_RD 32 O or_alu_result 32 O or_ext_result 32
控制单元_CU
输入改为instr,之前为opcode和func
| 指令 | Opcode[31:26] | [25:21] | [20:16] | [15:11] | [10:6] | [5:0] |
|---|---|---|---|---|---|---|
| add | 000000 | rs | rt | rd | 00000 | 100000 |
| sub | 000000 | rs | rt | rd | 00000 | 100010 |
| ori | 001101 | rs | rt | immediate | ~ | ~ |
| lw | 100011 | base | rt | offset | ~ | ~ |
| sw | 101011 | base | rt | offset | ~ | ~ |
| beq | 000100 | rs | rt | offset | ~ | ~ |
| lui | 001111 | 00000 | rt | immediate | ~ | ~ |
| nop | 000000 | 0 | 0 |
分支转移实现
B 类指令
为了减少因控制冲突导致的暂停(stall),我们将 B 类指令的判断进行前置,单独使用 CMP 模块进行判断。当 B 类指令进入 D 级后(此时 F 级的指令为编译优化调度的指令),CMP 模块的判断结果进入 NPC,如过 CMP 结果为真(CMP_out = 1)而且 NPCOp 信号为 0x001(说明当前指令为 B 类指令),NPC 输出转移的地址 npc 并进入 IFU 的输入端,在下一时钟沿上升时进入 F 级,实现转移。
j 和 jal
当 j 或 jal 进入 D 级后(此时 F 级的指令为编译优化调度的指令),D_instr 中 imm26 域的数据进入 NPC 进行处理,如果当前 NPCOp 信号为 0x010(说明当前指令为 jal 或 j 指令),NPC 输出转移的地址 npc,并进入 IFU 的输入端,在下一时钟沿上升时进入 F 级,实现转移。
jal 指令在实现跳转的同时,还需要将下一条指令的地址存入 31 号寄存器中,因此我们需要在 IFU 中计算出改地址,并随着 jal 指令进行流水,最终在 W 级写入 GRF 的 31 号寄存器。由于存在延迟槽,pc+4 地址中的指令是编译优化机制调度过来的,因此我们要保存的地址应该为 pc+8。
jr
当 jr 进入 D 级后(此时 F 级的指令为编译优化调度的指令),D_V1_f(经过转发后的 D_V1 值)进入 NPC,如果当前 NPCOp 信号为 0x011(说明当前指令为 jr 指令),NPC 输出转移的地址 npc,并进入 IFU 的输入端,在下一时钟沿上升时进入 F 级,实现转移。
冒险处理
冒险处理我们均通过 “A_T” 法实现 ——
转发(forward)
无脑转发策略。
将所有在该层级后面的均进行转发。
比如ID级流水,需要用到D_rs和D_rt的对应寄存器的值。对于写入寄存器的值,可能为E级中的,E_alu_result, M_mem_writeData。
当前面的指令要写寄存器但还未写入,而后面的指令需要用到没有被写入的值时,这时候会产生数据冒险,我们首先考虑进行转发。我们假设所有的数据冒险均可通过转发解决。也就是说,当某一指令前进到必须使用某一寄存器的值的流水阶段时,这个寄存器的值一定已经产生,并存储于后续某个流水线寄存器中。
在这一阶段,我们不管需要的值有没由计算出,都要进行转发,即暴力转发。为实现这一机制,我们要清楚哪些模块需要转发后的数据(需求者)和保存着写入值的流水寄存器(供应者)
-
供应者及其产生的数据
流水级 产生数据 MUX 名 & 选择信号名 MUX 输出名 E E_E32,E_pc8 MUX_E_out & SelEMOut E_out M M_AO,M_pc8 MUX_M_out & SelEMOut M_out W W_AO,W_RD,W_pc8 MUX_W_out & SelWOut W_out -
需求者及其产生的数据
接收端口 选择数据 HMUX 名 & 选择信号名 MUX 输出名 CMP_D1/NPC_ra D_V1,M_out,E_out HMUX_CMP_D1 & FwdCMPD1 D_V1_f CMP_D2 D_v1,M_out,E_out HMUX_CMP_D2 & FwdCMPD2 D_V2_f ALU_A E_V1, W_out,M_out HMUX_ALU_A & FwdALUA E_V1_f ALU_B E_V2,W_out,M_out HMUX_ALU_B & FwdALUB E_V1_f DM_WD M_V2, W_out HMUX_DM & FwdDM M_V2_f
从上表可以看出,W 级中的数据没有转发到 D 级,原因是我们在 GRF 内实现了内部转发机制,将 GRF 输入端的数据(还未写入)及时反映到 RD1 或这 RD2,判断条件为 A3 == A2 或者 A3 == A1。
此时为了生成 HMUX 的选择信号,我们需要向 HCU(冒险控制器)输入”A” 数据,然后进行选择信号的计算,执行转发的条件为 ——
- 前位点的读取寄存器地址和某转发输入来源的写入寄存器地址相等且不为 0
- 写使能信号有效
根据以上条件我们可以生成上面的 5 个 HMUX 选择信号,选择信号的输出值应遵循 “就近原则”,及最先产生的数据最先被转发。
暂停(stall)
接下来,我们来处理通过转发不能处理的数据冒险。在这种情况下,新的数据还未来得及产生。我们只能暂停流水线,等待新的数据产生。为了方便处理,我们仅仅为 D 级的指令进行暂停处理。
我们把 Tuse 和 Tnew 作为暂停的判断依据 ——
- Tuse:指令进入 D 级后,其后的某个功能部件再经过多少时钟周期就必须要使用寄存器值。对于有两个操作数的指令,其每个操作数的 Tuse 值可能不等(如 store 型指令 rs、rt 的 Tuse 分别为 1 和 2 )。
- Tnew:位于 E 级及其后各级的指令,再经过多少周期就能够产生要写入寄存器的结果。在我们目前的 CPU 中,W 级的指令 Tnew 恒为 0;对于同一条指令,Tnew@M = max (Tnew@E - 1, 0)
在这一阶段,我们找到 D 级生成的 Tuse_rs 和 Tuse_rt 和在 E,M,W 级寄存器中流水的 Tnew_D,Tnew_M,Tnew_W,如下表所示
-
Tuse 表
指令类型 Tuse_rs Tuse_rt calc_R 1 1 calc_I 1 X shift X 1 shiftv 1 1 load 1 X store 1 2 branch 0 0 jump X X jr 0 X -
Tnew 表
指令类型 Tnew_D Tnew_E Tnew_M Tnew_W calc_R 2 1 0 0 calc_I 2 1 0 0 shift 2 1 0 0 shiftv 2 1 0 0 load 3 2 1 0 store X X X X branch X X X X jal 0 0 0 0 jr X X X X lui 1 0 0 0
然后我们 Tnew 和 Tuse 传入 HCU(冒险控制器中),然后进行 stall 信号的计算。如果 Tnew > TuseHCU 中的 stall 信号值为 1,此时执行以下操作 ——
- 冻结 PC 寄存器(IFU_en = ~stall = 0)
- 冻结 D 级寄存器(D_en = ~stall = 0)
- 清空 E 级寄存器(E_clr = stall = 1)
碎碎念
-
关于slt
下面这种是错的
wire [31:0] signed_srcA, signed_srcB; assign signed_srcB = $signed(i_srcB); assign signed_srcA = $signed(i_srcA); (i_aluOp == `ALU_slt ) ? ( signed_srcA < signed_srcB):但是这种是对的
(i_aluOp == `ALU_slt ) ? ( $signed(i_srcA) < $signed(i_srcB)): -
关于lb
不知道这个为什么会有问题
# def.v: `define GRF_WD_PC4 3'b000 `define GRF_WD_PC8 3'b001 `define GRF_WD_ALU_RESULT 3'b010 `define GRF_WD_MEM_RD 3'b011 `define GRF_WD_EXT 3'b100 `define GRF_WD_MDU_RESULT 3'b101 # CU.v: assign o_grf_WD_Sel = (o_load ) ? `GRF_WD_MEM_RD : (o_calc_r | o_calc_i) ? `GRF_WD_ALU_RESULT : (o_mf ) ? `GRF_WD_MDU_RESULT : (o_link ) ? `GRF_WD_PC8 : (o_lui ) ? `GRF_WD_EXT : `GRF_WD_ALU_RESULT ;这个W级CU的控制信号(我采用的是分布式译码),然后本来是o_calc_r和o_calc_i那个是第一行,为了测试调整了一下,按照仿真结果
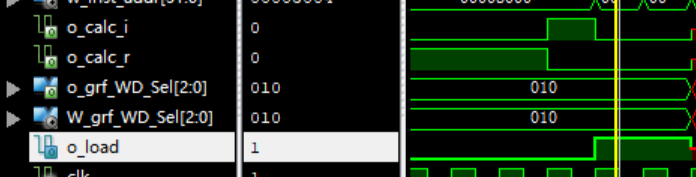
o_load确实是1,但是为什么这个Sel(grf的写入数据写入信号)为什么还是010(也就是ALU的那个呀)
测试代码如下:

标准输出:
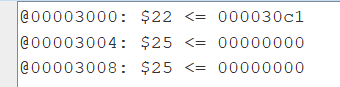
我的输出:
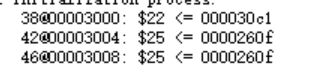
这个0x0000260f正好就是alu_result也就是计算得到的lb的地址
-
bne
# def.v `define NPC_PC4 3'b000 `define NPC_BRANCH 3'b001 `define NPC_J 3'b010 `define NPC_JR 3'b011 # CU.v assign o_npcOp = (o_b_type ) ? `NPC_BRANCH : (o_j_imm26) ? `NPC_J : (o_j_r ) ? `NPC_JR : `NPC_PC4;也出现了类似上面的情况

也就是o_b_type为1,但是npcOp仍然是PC4的000,而不是001
思考题
1、为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
- 乘除法都有较高的延迟,若整合进 ALU,则进行乘除法的时候,所有的运算类指令都只能阻塞在 D 级,造成了极大的性能损失。单独设置 MDU 的话,无关的指令还能正常的在 ALU 运行,效率较高。
- HI,LO 寄存器并不是通用寄存器,和其他通用寄存器的用法不一致,不能通过非乘除法指令修改和访问,因此不需要置于 GRF 中,内置在 MDU 中即可。
2、真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
-
真实的流水线 CPU 采用的乘法是有加法器和移位器循环,具体实现过程为:
首先 CPU 会初始化三个通用寄存器用来存放被乘数,乘数,部分积。
部分积寄存器初始化为 0。
判断乘数寄存器的低位是 0|1,如果为 0 则将乘数寄存器右移一位,同时将部分积寄存器也右移一位。
在位移时遵循计算机位移规则,乘数寄存器低位溢出的一位丢弃,部分积寄存器低位溢出的一位填充到乘数寄存器的高位。
同时部分积寄存器高位补 0。如果为 1 则将部分积寄存器加上被乘数寄存器,再进行移位操作。
当所有乘数位处理完成后部分积寄存器做高位,乘数寄存器做低位就是最终乘法结果。 -
还有另一种乘法的方式:
只需两个寄存器,A [31:0],B [63:0],A 初始化为被乘数,B 初始化为乘数。
每一次取 B 的最低位,为 1 则将 A [31:0]+B [63:32] -> B [63:32],为 0 则不操作。
每次将 B >> 1,然后高位补 0。 -
除法实现:
与乘法的操作基本相反,首先 CPU 会初始化三个寄存器,用来存放被除数,除数,部分商。余数 (被除数与除数比较的结果) 放到被除数的有效高位上。CPU 做除法时和做除法时是相反的,乘法是右移,除法是左移,乘法做的是加法,除法做的是减法。首先 CPU 会把被除数 bit 位与除数 bit 位对齐,然后再让对齐的被除数与除数比较 (双符号位判断)。比如 01-10=11 (前面的 1 是符号位) 1-2=-1 计算机通过符号位和后一位的 bit 位来判断大于和小于,那么 01-10=11 就说明 01 小于 10,如果得数为 01 就代表大于,如果得数为 00 代表等于。如果得数大于或等于则将比较的结果放到被除数的有效高位上然后再商寄存器上商:1 并向后多看一位 (上商就是将商的最低位左移 1 位腾出商寄存器最低位上新的商) 如果得数小于则上商:0 并向后多看一位然后循环做以上操作当所有的被除数都处理完后,商做结果被除数里面的值就是余数。
3、请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
- 除 cnt—,和 BusyReg 置位以外全是组合逻辑的操作(不然可能会多出来一个空周期)
- 对于乘除指令:
- 将 Busy,start_E,MDUOp_D 传入 HCU
- 然后 md 暂停信号为
(Busy | start_E) & (MDUOp_D != 0)
4、请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
- 对于需要写入的位置更加的直观,相当于将 DMWE、DMOP 写入的 A [1:0] 用四位字节使能信号表示,十分的统一。
5、请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
- 按字节读写的时候,我们获得的是一字节,但是我们如果要 lw 或 lh 的话我们就需要拼接。如果是 sw 或 sh 的话我们需要多次存入。
- 若用 lb,sb,lh,sh 这种非取字的读写时,按字节读可以省去,取位,拼接的步骤,效率要优于按字读写。
6、为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
- 我们根据不同指令之间的相似性将指令分成了几类 ——calc_R、calc_I、shift、shiftv、load、store、B 类、J 类、md 类、mf 类、mt 类, 并设置对应信号帮助译码,防止计算表达式过长,而且在处理数据冲突时我们只需要将表示该类的信号写入表达式即可。此外,我们将相似功能的控制信号用一个多位宽信号来表示,如针对 DM 的访存功能,我们设置一个 3 位 LSOp 信号;针对乘除槽中的 md、mf、mt 功能,我们设置一个 MDUOp 信号来控制,从而减少了流水寄存器的接口数目,从而降低复杂度。
7、在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
tuse和tnew部分有
8、如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
白嫖捏

