OO第一单元-表达式化简总结
0 前言
作业简介
本次作业要求对表达式进行恒等变形,要求只保留必要的括号并使得表达式的长度尽量的短
本次作业用到了递归下降法进行表达式解析和层次化程序设计的思想。
首先说明自己用到的一些名词的特定含义
- 表达式Expr:特指只经过解析后得到的式子
- 多项式Poly:指解析并去括号后得到的式子
- 单项式Mono:指构成多项式的基本单元,多项式为一个或多个单项式相加
下面对自己的架构和整体作业设计进行分享
1 架构设计体验心得
最终架构如下:
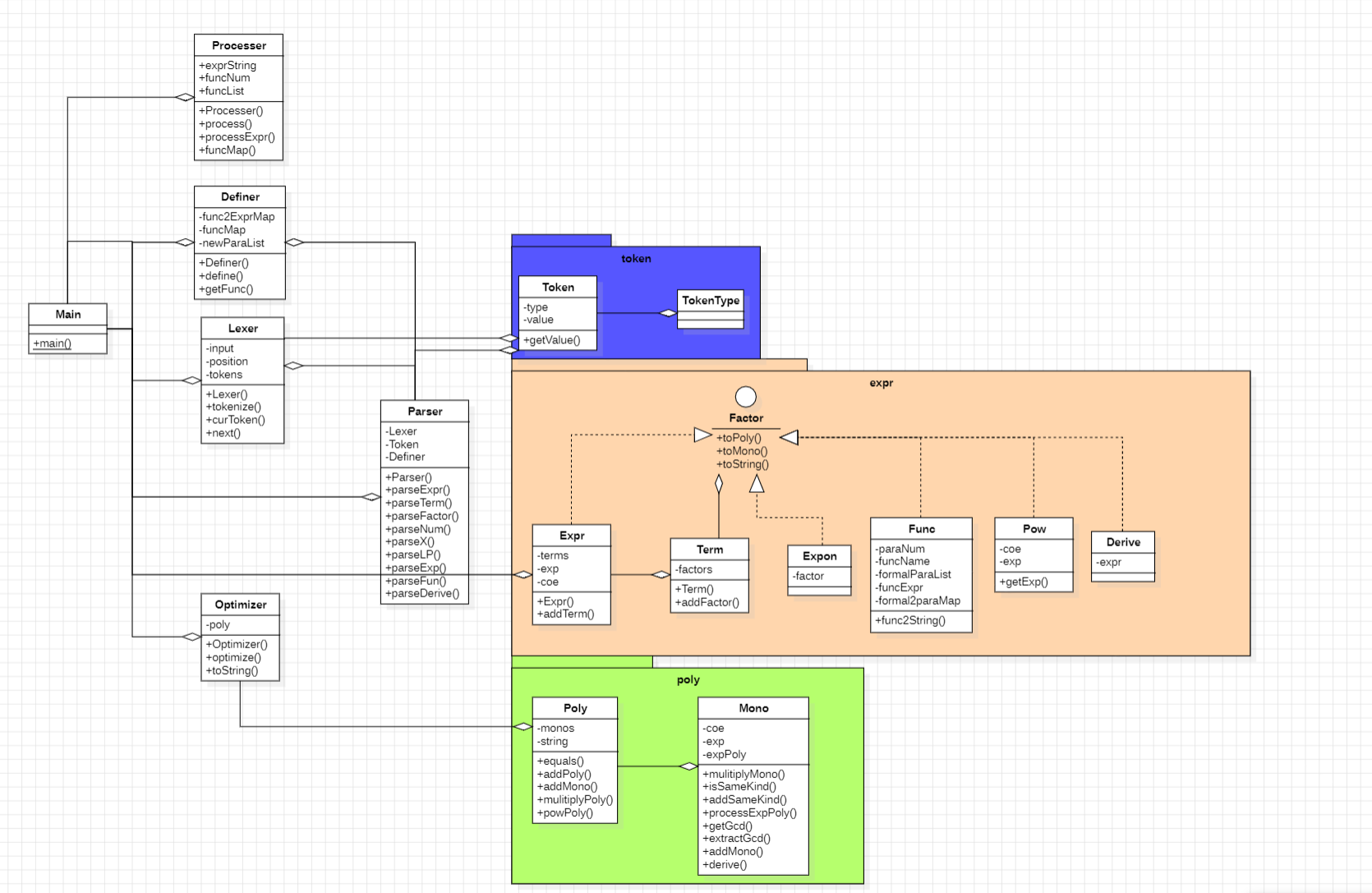

本单元主要是为了进行层次化进行架构设计的学习和应用。
首先是整体的层次化处理方法,Lexer-Parser-Optimizer的结构,Lexer为Parser提供词法单元,Parser为Optimizer提供解析后的表达式Expr,Optimizer最后将结果字符串输出。
还有Parser内部的层次化结构,从parseExpr调用parseTerm,再在parseTerm中调用parseFactor,而parseFactor中又包含多种因子,其中还包括对parseExpr的递归调用。
从数据结构和功能结构的角度进行分析:
-
数据结构层次
数据结构主要是解析得到的抽象语法树结构,设计了Expr表达式类作为解析得到的结果,Expr中存储多个Term,与Term形成聚合关系;Term中存储多个Factor,与Factor形成聚合关系
-
功能结构层次
功能层次主要是进行运算,进行括号化简,设计了Poly多项式进行运算,Poly中存储多个Mono,与Mono形成聚合关系。在进行调用Poly的multiplyPoly的方法时,调用multiplyMono方法,层次化清楚,每个方法的功能作用也更加明确。

1.1 第一次作业
本次作业要求完成简单的表达式化简问题,表达式中仅含有加、减、乘、乘方等基本操作,一方面是结合自己的踩坑经历,另一方面是考虑到递归下降法良好的可拓展性,我果断选择使用递归下降法作为表达式解析的主要方法。
以下是代码架构的主体部分:
- Processer将输入的表达式字符串进行化简处理后得到新的表达式字符串
- Lexer得到当前词法单元,将词法单元传递给Parser进行解析
- Parser 对表达式进行解析,得到expr
- expr调用toPoly后,得到多项式poly
- Optimizer对poly进行优化输出,得到结果的字符串


语法分析:
首先我们看一下设定的形式化表述
- 表达式 →→ 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
- 项 →→ [加减 空白项] 因子 | 项 空白项 ‘*’ 空白项 因子
- 因子 →→ 变量因子 | 常数因子 | 表达式因子
- 变量因子 →→ 幂函数
- 常数因子 →→ 带符号的整数
- 表达式因子 →→ ‘(’ 表达式 ‘)’ [空白项 指数]
- 幂函数 →→ ‘x’ [空白项 指数]
简单来看,我们可以大体上设计这么几个部分:
-
Factor:因子,包括变量因子(包括幂函数),常数因子,表达式因子 -
Term:项,由乘法运算符连接的因子组成 -
Expr:表达式,由+-连接的项组成 -
空白字符:space-ascii=32,tab-ascii=9
可以简单分析得到空白字符可以直接去掉,一个是考虑到有效字符的部分不计算空白字符,同时不会产生什么影响,于是可以直接不处理空白字符。同时空白字符在词法单元时并不会在区分特定的词法之间起到任何的作用,不会影响运行的优先级以及每个词法单元的特定含义。
这里举个不能去掉空白字符的例子,比如
shell中echo=1与echo = 1的区别,前者是作为赋值符号,后者是作为参数传递,如果去掉空格,二者无法区分。
Processer
预处理器,对输入的字符串进行预处理,使得后面的递归下降法的使用更加便于进行。
预处理部分包括:
- 去除所有空白字符
- 化简合并连续的
+-符号 - 除去前导0,这个我也没有处理,直接使用
BigInteger处理就行 - 同时可以化简
^+为^ (+)为(),也就是除去括号后的正号,这个我并没有进行了
这里讲一下我的预处理的方法,主要是第二个化简合并连续的+-符号,通过互测中的代码观察,$\frac78$的同学进行了除去空白字符,$\frac38$的同学合并了连续的+-号,合并的方法基本上都是遍历一遍字符串然后进行判断,这里我的方法是使用六次字符串的replaceAll方法
input = input.replaceAll("--", "+"); // 将连续的两个- 化为一个 +,那么之后在生成-前不会有连续的-号
input = input.replaceAll("\\+\\+", "+"); // 将连续的两个- 化为一个 +,那么之后在生成+前不会有连续的+号
input = input.replaceAll("-\\+", "-"); //
input = input.replaceAll("\\+-", "-"); // 将正负交替的 +- 化为一个 -
input = input.replaceAll("--","+"); // 由于生成了- ,可能会有两个--连续的情况
input = input.replaceAll("\\+\\+", "+"); // 即可处理完毕这么处理可能写起来方便的一点,但是时间上可能会是直接遍历的几倍(\流泪)
这里想分析一下为什么说会便于进行,我认为主要在于对设定的形式化表述可以进行优化。
在预处理完之后我们的形式化表述变为:
- 表达式 →→ 项 | 表达式 加 项
- 项 →→ [加减 ] 因子 | 项 ‘*’ 因子
- 因子 →→ 变量因子 | 常数因子 | 表达式因子
- 变量因子 →→ 幂函数 x | x^b
- 常数因子 →→ 带符号的整数
- 表达式因子 →→ ‘(’ 表达式 ‘)’ [ 指数]
- 幂函数 →→ ‘x’ [ 指数]
采取向前靠的策略,可以发现现在已经变成了,表达式就是多个项相加(已经没有减这种情况了),项就是多个因子相乘,那么这时我们对于Expr表达式的构造就可以不需要记录符号了(这也就是我第一次的错误思路的来由),具体来说,Expr里面只需要存Term就行,不需要存BinOp,因为每个运算都是加法。
这个时候我们可以想到的数据结构就可以是HashSet来实现了。
在后续的作业中发现HashSet由于访问顺序的不确定,可能会出现一些奇怪的bug,因此后来采用的是ArrayList作为容器。至于HashSet的bug的具体原因,打算之后再进行具体研究分析。
Lexer
词法分析器,功能是解析出表达式的每个token,那么分析词法单元的思路主要有两种,一个是只保存当前的token,另一个是先将所有token全部存放在一个容器中,然后每次去取即可。当时处理的时候考虑的是先一次性将所有token解析好,有更好的空间连续性,更加优雅也没有具体分析,二者都可以
idea1:根据前一个是什么,判断下一个的区间,得到当前token
curTokenidea2:直接先全部解析出来,放到一个数据结构里面,然后只需要get_next
简单分析一下:
在这里我们其实每次都只需要用到
curToken就行,如果要全部存起来,使用的数据结构可以直接使用一个ArrayList即可。因此我便采用了这种处理。
这里我们在使用lexer的时候主要包括getCurToken或者getNextToken,xcgg在博客也提到了要注意这个,但是具体怎么处理了。
我是这么处理的,我使用了两个方法
public Token curToken() {
return tokens.get(position);
}
public void next() {
position++;
}由于我是先将所有的Token解析出来,然后再依次取每一个curToken,这么处理的一个理由是我想着这样先把字符串一次性处理或许会有更好的数据连续性,然后会有需要判curToken的类型的部分,每次判断成功后,调用next方法,这样就可以确保我的每一次判断都是在我进入了下一个层次后再修改的position。或许更容易理解一些~~
Parser
解析器,采用递归下降法进行解析。
首先我们容易建立这三个层级的解析方法
public Expr parseExpr(int signal);
public Term parseTerm(int signal);
public Factor parseFactor(int signal);这里加入了signal这个元素,是为了方便的将符号一步步进到底层进行处理
同时在解析式我并没有处理表达式的幂的运算,于是在Expr中添加了exp这个属性。
于是这里就递归的将表达式解析好了,现在我们看
Expr,他就是一个Term的HashSet,只需要处理好了这些Term那么这个Expr就处理好了~Term同理
最关键的部分,同时也是相对比较难处理的一部分就是消括号,我在这里使用到了Poly和Mono两个类来处理。
Poly是多项式类,Mono是单项式类,其实从功能上讲只有一个Poly就够了,新添一个Mono方便实现Poly的相加和相乘~
在Expr和Term中实现了toPoly的方法
public Poly toPoly();在Factor中实现了toMono方法
public Mono toMono();在转化是处理Expr的幂次实际上就是调用Poly的pow方法
public Poly powPoly(BigInteger exp);Optimizer
优化,目前主要包括两个点
- 重写Mono的toString方法,化简每一个单项式,通过特判系数为0,1,-1的情况,以及x的指数为0,1的情况即可。
- 在Optimizer中得到Poly的字符串时,调整顺序,尽量使得正项在第一个。可以通过将每一个Mono的string存在一个ArrayList中,然后判断是否存在正项,然后将该项放在前面,其余项顺序输出即可。
1.2 第二次作业
在仔细分析下,第二次作业的两大难点是:
- 自定义函数的处理
- exp的化简与合并同类项
对此的处理策略是:
- 结合C语言中对于自定义函数的处理策略中的一个是进行值传递,我们将实参解析后直接进行字符串层级的替换,然后将最后得到的因子作为一个表达式因子进行解析。首先将自定义函数作为一个因子进行处理,将里面的每一个实参作为一个表达式进行解析,使用词法分析器,可以自然的处理对于逗号和括号的判断,得到表达式后转化为字符串,在函数中进行字符串层级的替换后,再次生成一个词法分析器和解析器得到一个表达式,作为表达式因子并完成解析

- 为了合并同类项,需要判断指数函数的两个表达式是否是同类项,需要添加两个判断Poly相等的办法,我使用的是将两个Poly相减,如果得到的结果为空,那么两个表达式就是相等。而我们在第一次作业就已经实现了Poly的add和multiply方法,我们只需要增加一个toNegate取相反数的方法然后再次调用已有的add方法即可。这种策略符合我们的对拓展开放,对修改封闭的开闭原则。
下面对两种处理策略进行详细论述。
首先是在definer中对于函数的实参和形参的转化采取如下的方法,这里主要是为了解决几个问题:
- x,y,z这几个形参在函数定义式中的顺序不固定,不便于传入实参后的实际处理
- 将函数形式更加规范化
于是采取一下策略对函数进行预处理:

对于判断两个单项式Mono是否为同类项来进行合并同类项的方法:
public static boolean isSameKind(Mono mono1, Mono mono2) {
if (mono1.getExp().compareTo(mono2.getExp()) != 0) {
return false;
}
Poly expPoly1 = mono1.getExpPoly();
Poly expPoly2 = mono2.getExpPoly();
Poly result = new Poly();
result = expPoly2.toNegate(expPoly2);
result = result.addPoly(result, expPoly1);
if (result.isEmpty()) {
return true;
}
return false;
}这里用到静态方法,提高了函数的调用效率。
1.3 第三次作业
本次作业在我的架构下的实现相对比较简单。仅修改了约70行即完成任务。
首先是关于自定义函数的嵌套,根据1.2中关于我对自定义函数处理的论述可以看出,我对于自定义函数的处理可以自然的处理函数定义式的嵌套。
关于求导,我只做了两件事情。
-
新添了继承于
Factor的Derive导数类进行解析-
public class Derive implements Factor { private Expr expr; public Derive(Expr expr) { this.expr = expr; } }`Derive`中只需要有一个expr的属性即可 2. 给`Poly Mono`增加了一个求导的方法 - `Poly`中只需要递归解析`Mono`即可 - `Mono`中模拟即可 $$ \begin{align} &b\ne 0 ;dx(a*x^b*exp(Poly))=a*b*x^{b-1}*exp(Poly)+a*x^b*exp(Poly)*dx(Poly)\\ \\ &b =0;d(a*exp(Poly)) = a*exp(Poly)*dx(Poly) \end{align} $$ 然后递归调用poly的求导方法即可 那么就可以完成本次作业。 以下是本次作业之后的架构: 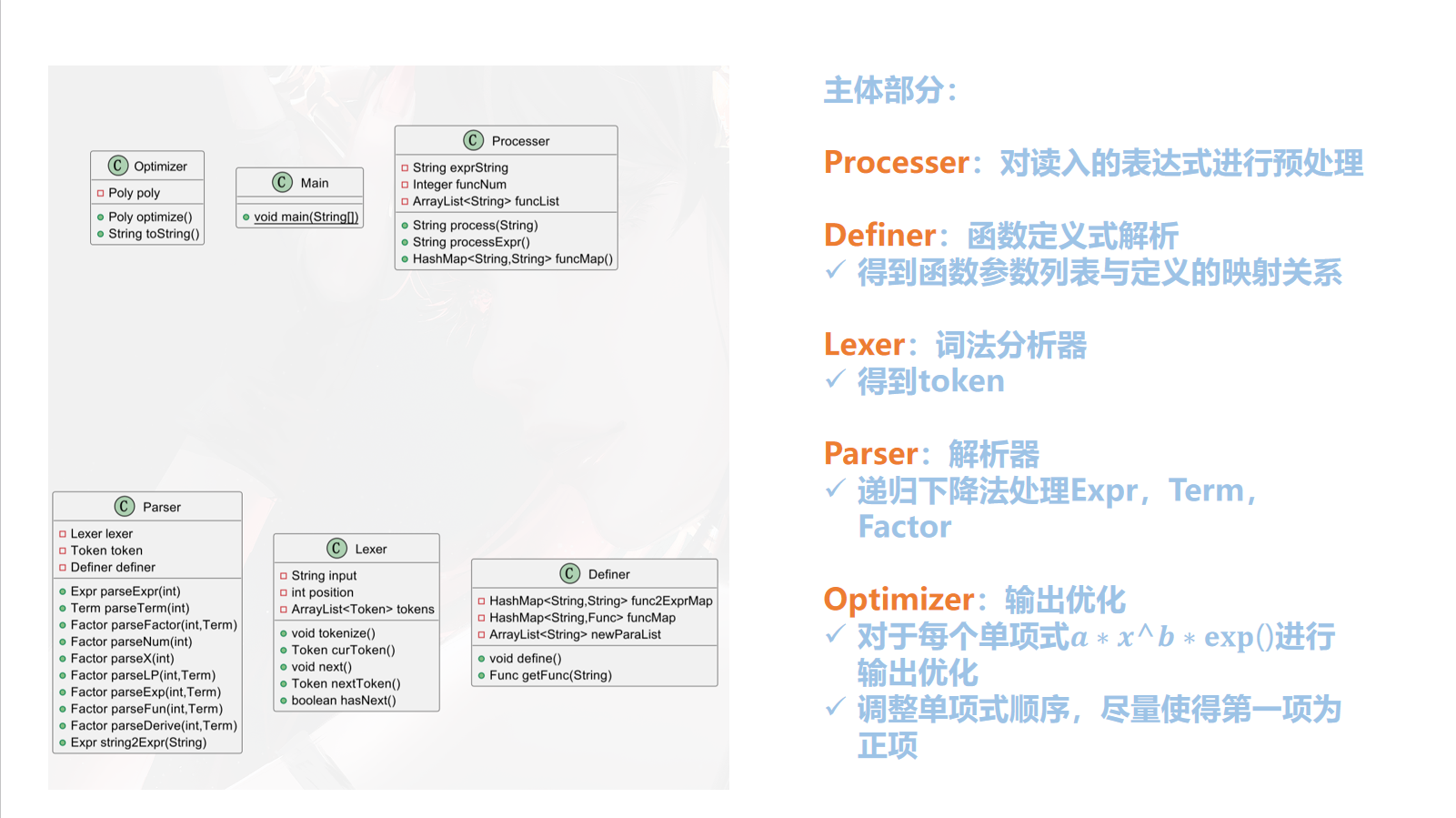 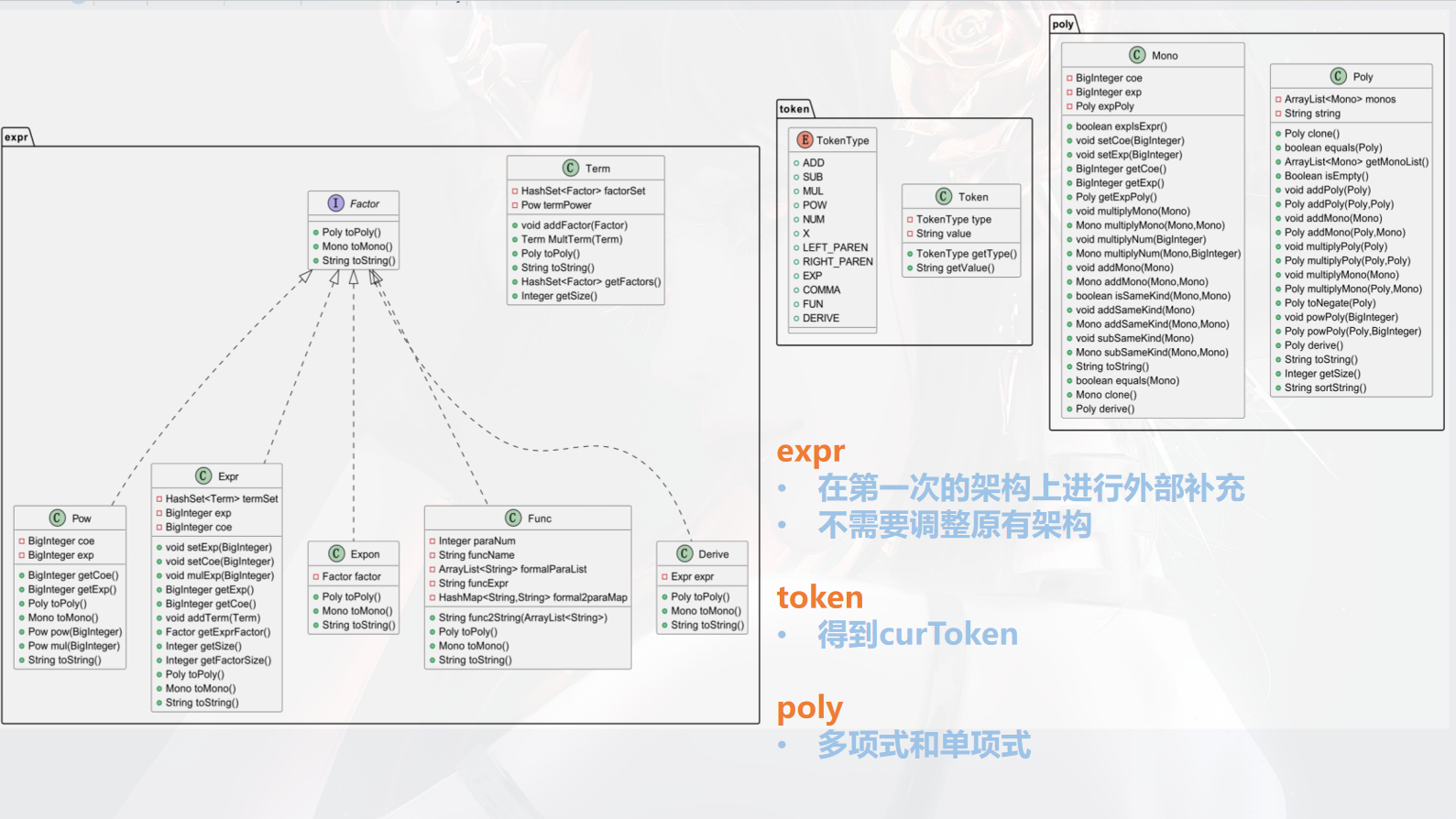 ## 2 基于度量的程序架构分析 ### 2.1 代码量 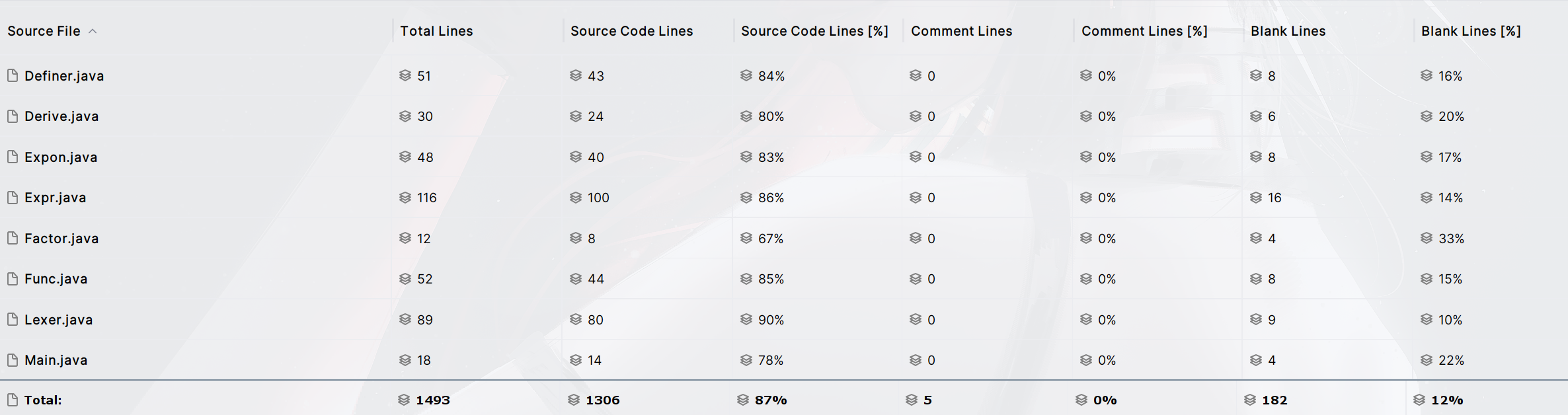 ### 2.2 方法复杂度 > 使用IDEA的MetrcisReloaded插件进行分析 - ev(G) 基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。 - iv(G) 模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。 - v(G) 是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。 **项目复杂度/模块复杂度** | project/module | v(G)avg | v(G)tot | | -------------- | ------- | ------- | | Expression | 2.86 | 352 | **包复杂度** | package | v(G)avg | v(G)tot | | ------- | ------- | ------- | | . | 3.71 | 104 | | expr | 1.86 | 82 | | poly | 3.40 | 163 | | token | 1.00 | 3 | **类复杂度** | class | OCavg | OCmax | WMC | | --------------- | ----- | ----- | ---- | | Definer | 2.0 | 4.0 | 6.0 | | expr.Derive | 1.0 | 1.0 | 4.0 | | expr.Expon | 1.75 | 4.0 | 7.0 | | expr.Expr | 2.0 | 11.0 | 30.0 | | expr.Func | 1.4 | 3.0 | 7.0 | | expr.Pow | 2.125 | 10.0 | 17.0 | | expr.Term | 2.125 | 7.0 | 17.0 | | Lexer | 3.83 | 16.0 | 23.0 | | Main | 1.0 | 1.0 | 1.0 | | Optimizer | 6.33 | 9.0 | 19.0 | | Parser | 3.54 | 9.0 | 39.0 | | poly.Mono | 2.75 | 14.0 | 77.0 | | poly.Poly | 3.4 | 10.0 | 68.0 | | Processer | 1.5 | 2.0 | 6.0 | | token.Token | 1.0 | 1.0 | 3.0 | | token.TokenType | | | 0.0 | **方法复杂度** | method | CogC | ev(G) | iv(G) | v(G) | | -------------------------------------- | ---- | ------- | ----- | ---- | | Processer.funcMap() | 1.0 | 1.0 | 2.0 | 2.0 | | | | | | | | Definer.define() | 5.0 | 1.0 | 4.0 | 4.0 | | | | | | | | Lexer.tokenize() | 22.0 | **5.0** | 15.0 | 18.0 | | Lexer.curToken() | 1.0 | 2.0 | 1.0 | 2.0 | | | | | | | | Parser.parseExpr(int) | 9.0 | 5.0 | 6.0 | 7.0 | | Parser.parseTerm(int) | 9.0 | 3.0 | 7.0 | 7.0 | | Parser.parseFactor(int, Term) | 10.0 | 7.0 | 11.0 | 11.0 | | | | | | | | expr.Expr.toString() | 30.0 | 10.0 | 10.0 | 11.0 | | expr.Term.toString() | 7.0 | 2.0 | 4.0 | 4.0 | | expr.Expon.toString() | 6.0 | 1.0 | 4.0 | 4.0 | | expr.Pow.toString() | 16.0 | 10.0 | 8.0 | 10.0 | | expr.Term.toPoly() | 10.0 | 1.0 | 7.0 | 7.0 | | expr.Expr.toPoly() | 3.0 | 1.0 | 3.0 | 3.0 | | | | | | | | poly.Mono.equals(Mono) | 4.0 | 5.0 | 4.0 | 5.0 | | poly.Mono.isSameKind(Mono, Mono) | 2.0 | 3.0 | 1.0 | 3.0 | | poly.Mono.derive() | 2.0 | 2.0 | 2.0 | 2.0 | | poly.Mono.processExpPoly(Poly, String) | 25.0 | 3.0 | 15.0 | 16.0 | | poly.Mono.toString() | 30.0 | **8.0** | 17.0 | 18.0 | | poly.Poly.addMono(Mono) | 6.0 | 4.0 | 4.0 | 4.0 | | | | | | | | poly.Poly.equals(Poly) | 17.0 | 7.0 | 8.0 | 9.0 | | poly.Poly.addMono(Poly, Mono) | 8.0 | 4.0 | 6.0 | 6.0 | | poly.Poly.addPoly(Poly) | 1.0 | 1.0 | 2.0 | 2.0 | | poly.Poly.multiplyMono(Mono) | 1.0 | 1.0 | 2.0 | 2.0 | | poly.Poly.multiplyPoly(Poly) | 3.0 | 1.0 | 3.0 | 3.0 | | poly.Poly.powPoly(BigInteger) | 2.0 | 2.0 | 3.0 | 3.0 | | poly.Poly.derive() | 1.0 | 1.0 | 2.0 | 2.0 | | poly.Poly.toString() | 21.0 | 5.0 | 8.0 | 11.0 | | | | | | | | Optimizer.optimize() | 21.0 | 8.0 | 9.0 | 9.0 | | Optimizer.toString() | 18.0 | 5.0 | 8.0 | 10.0 | 这里主要分析ev(G)指标,基本圈复杂度。下面对几个基本圈复杂度较高的方法提出解决办法: - Lexer.tokenize(),ev(G)=5 这里主要是采用了多个if分支判断是什么词法类型,这里可以对于除数字外的其他类型添加一个Char向Token的一个映射,然后直接取对应key的value即可 - Lexer.tokenize(),ev(G)=7 这里同样也是用到了多个if分支判断是什么因子类型,同样可以建立TokenType向方法的一个映射 - poly.Mono.toString(),ev(G)=8 这里方法复杂度高的一个重要原因是在其中调用了提取公因式的方法,加上本身的多个对于系数和指数的判断,方法复杂度较高,对此可以采取将toString方法中的几个处理提取方法出来,将功能进行进一步的划分。 这一些方法的复杂度较高,容易导致出现: 1. 使用大量if分支判断,包括可能用到instanceof,不符合开闭原则,没有好的拓展性 2. 容易导致bug难找 ## 3 个人bug分析与踩坑经历 ### 3.1 个人架构调整 在最开始,我希望通过自己独立的思考来解决表达式解析的过程,于是考虑到不同因子之间可能使用加号或者减号连接起来,如果使用一个ArrayList来将这些因子之间的符号连接起来就很麻烦,于是我想到可以建立一棵表达式树,用运算符作为中间结点讲不同的因子连接起来。也就是下面这种结构 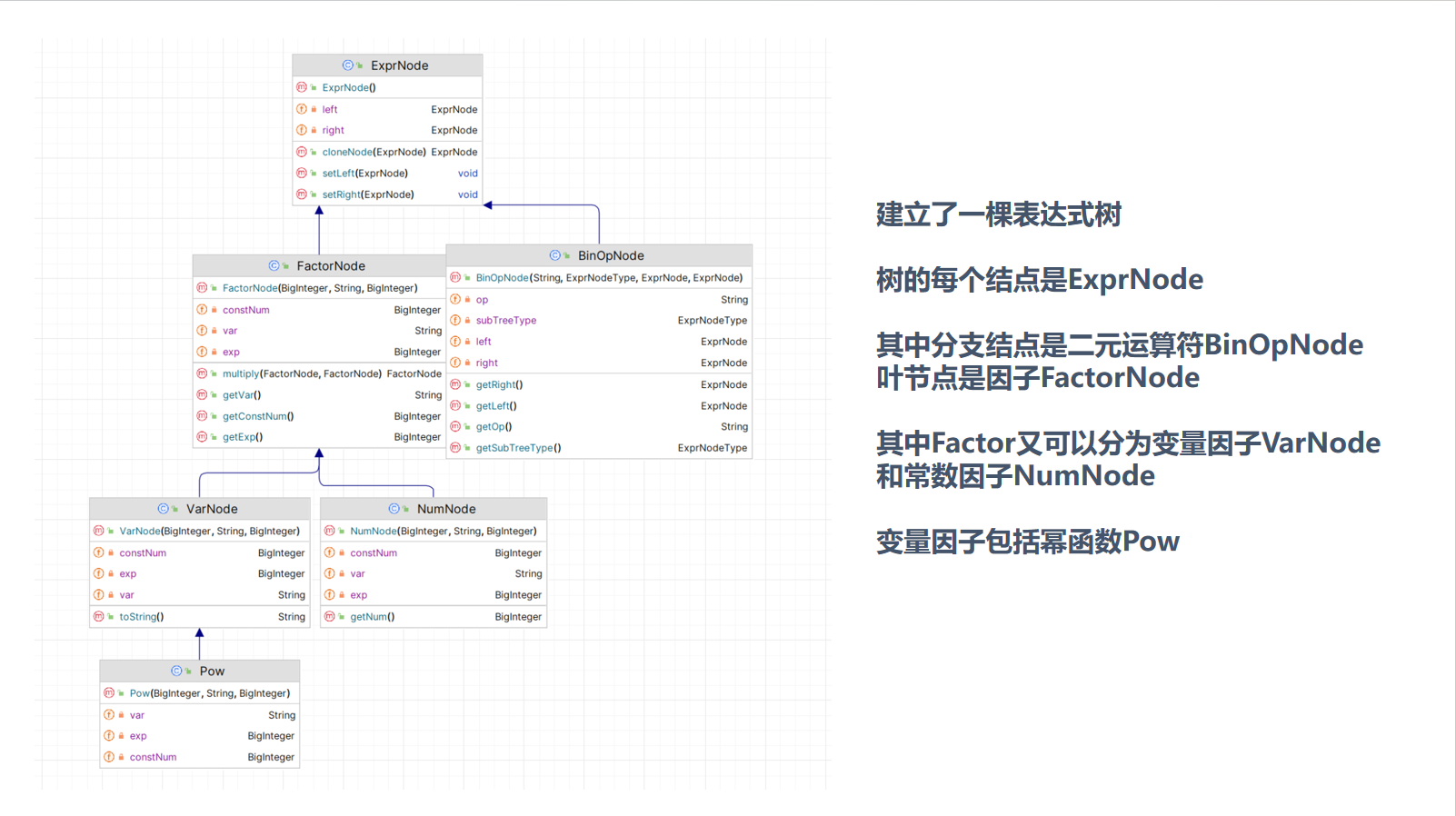 > 首先分析自己一下之前的架构的不好的地方,或者说应该是麻烦的地方,有很多地方我没有处理好导致问题不断复杂化 这里两种架构我认为一个重要的区别就是 - 第一种使用表达式树的方法是没有对最外层的`+-`号进行进一步处理,放到下一层去处理,于是需要像个办法把符号存下来,于是自然的想到了树的结构 - 第二种架构实际上是直接将`Expr`看成多个`Term`相加,`Term`里面带有正负号 其实单纯只是说解析时使用表达式树的方法也不是不行,也就是数据结构是能够将我所需要的这个层次结构表达出来,但是麻烦的点在于实现功能结构 > 功能结构包括展开与合并 运算部分我认为最难处理的在于求一个表达式的幂。 在一个树与树的相乘中,需要判断每一个节点的`ExprNodeType`,进行计算时,首先需要`clone`深拷贝一个`result`出来,然后进行相乘时需要递归的处理。 - 由于是树的结构,会得到一个非常巨大的树,更容易爆内存,而且需要合适的内存回收 - 递归是还需要考虑中间的`BinOpNode`是加号还是减号 复杂度++ > 但是总归是可以实现的,只是我确实没能够在这五六天里面完成出来(哭!),多给我几个月肯定可以完成!(bushi) ### 3.2 bug分析 #### 第一次作业 我在第一次作业的过程中本来没有合并同类项,导致我再进行表达式之间的相加和相乘时容易导致内存爆炸。 关于这个炸内存的原因其实还可以仔细分析一下,我在`Expr`和`Term`中来存取`Term`和`Factor`的数据结构都是用到的`HashSet`,我们来看看`HashSet`的扩容机制。 通过查看`HashSet.add()`方法,发现直接调用的是`HashMap.put()`方法 ```java newCap = DEFAULT_INITIAL_CAPACITY; // 16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 0.75 * 16
-
这里是初始化长度,也就是new一个HashSet开始使用时会先拓展一个含有16个元素的空间
if (oldCap >= MAXIMUM_CAPACITY) { // 1 << 30
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold可以发现扩容时,会判断如果原容量超过了设定的最大值,那么就不会再进行扩容,也就是说理论上(空间足够大),HashSet的容量也只是1<<30个;而没有超过时,是进行翻倍增长。
也就是可能在扩容时会有大量的空间请求,在这个时候是最有可能爆空间的!
第二次作业
这次作业主要是自己对于Poly的powPoly的实现过程中想要实现快速幂的计算,其中需要出现result.multiplyPoly(result)这种形式,但是我再multiplyPoly的实现里面是认为this和newPoly不一样,也就是本身和需要相乘的数不一样的,但是当相同时,我的处理就会导致在遍历Poly的monos(单项式的HashSet)的时候,会改变自身的值,导致最后的结果不正确。
后来的解决措施就是直接放弃使用快速幂,直接一个个相乘。
同时发现二者速度相差不大,分析认为复杂度主要在于多个多项式相乘时项数过多时候的判断是否为同类项这里消耗了比较多的时间。
优化需谨慎!
在这次作业优化的时候会错误的将exp((-x^2))变为exp(-x^2)这种形式,这要是对于是否去掉括号的判断不够合理。
修改策略为使用正则表达式进行更进一步的判断:
String numRegex = "[-]?\\d+$";
String powRegex = "x(\\^\\d+)?$";
String expRegex = "^exp\\(.*\\)$";
if (expPolyString.matches(numRegex)
|| expPolyString.matches(powRegex)
|| (expPolyString.matches(expRegex) && expPoly.getSize() == 1)){
// do something
}第三次作业
我这多灾多难的表达式化简哇
这里时因为我在Expr中存取Term,在Term中存取Factor,在Poly中存取Mono时都是使用到的HashSet,但是由于HashSet访问顺序不固定的原因,导致在不同平台的运行结果不一样,而且有一些特殊的情况出现了问题。
-
解决措施:
将HashSet修改为ArrayList即可
4 发现别人bug所采用的策略
-
最常用的方法还是使用评测机来疯狂评测,发现bug后对评测数据进行层层化简,定位到具体的问题所在的地方
当然这也是我们自己debug的一个重要方法
-
通过构造一些极端的数据
比如说魔鬼的
exp(exp(exp(exp(exp(x)^8)^8)^8)^8)^8这种还有包括输入一个0是否正确处理,同时还有之后的自定义函数嵌套时,手动构造一些能够满足复杂度,同时会报TLE错误的数据,如
3 f(x) = exp(exp(exp(exp(exp(x)^8)^8)^8)^8)^8 g(x) = exp(exp(exp(exp(exp(f(x))^8)^8)^8)^8)^8 h(x) = exp(exp(exp(exp(exp(g(x))^8)^8)^8)^8)^8 h(h(h(x))) -
最有用的手段应该还是自己跑几组覆盖率较高的数据,对代码逐行用debug模式进行阅读,判断哪里的处理是不完善的。
同时这种手段还可以学习到对方的代码的架构和处理细节上的好的地方
5 分析自己的优化
-
对于
a*x^b*exp()中的a和b进行特判 -
对于
exp()括号内能否去掉一层括号进行分析,使用正则表达式进行匹配(上文已经提到) -
对于Mono的输出顺序进行调整,尽量保证正项在最前面,比如
-x+1是比1-x要多一个字符的 -
提取公因式处理
在
exp((2*x+2*x^2+2*x^3))中提取最大公因式出来得到exp((x+x^2+x^3))^2public String processExpPoly(Poly expPoly, String expPolyString); public static BigInteger getGcd(String polyString, ArrayList<Pair<BigInteger, String>> monoStringList); public static Pair<Integer, BigInteger> getBigInteger(String polyString, int oleIndex); public static Pair<BigInteger, String> extractGcd(String expPolyString);将处理细节提取函数出来,可以有效简化处理,同时将各部分功能分得更加清晰,同时提高可拓展性,比如
extracGcd中,可以不止提取最大公因式,还可以将最大公因式的其他因子进行提出。
6 心得体会
首先是学习到了很多关于git的使用技巧,收益匪浅。

具体使用上:
- 在master分支上是主要部分的commit
- 在dev上可以commit很多零散的,阶段性完成后,在master段进行merge
- 当dev分支有问题时,在debug分支进行处理,解决后merge到dev分支
- 在debug时可以在print分支添加一些print的方法,然后debug修改了需要看结果是否符合是,merge到print分支即可
第一次写这么大一个项目,让我在知识层面上学到了很多关于层次化程序设计和递归下降法。学到更多的是自己对于架构的设计以及自己面对一个大工程是debug的一些方法。
同时,我也意识到自己的思考还是非常重要的,自己思考的架构能够有更加清楚的理解,也会有更多的收获!!
整体体验非常好,同时也意识到了自己的部分能力的不足,以后会进一步提升的!!
7 未来方向
第一单元整体质量很高!nrjj和lqgg yyds!,让人感受到OO很大的快乐哈哈哈,提升了个人的代码能力。
以下是几点简单的建议
- 可以在博客周将一些架构很好的代码进行分享
- 第三单元感觉难度骤降有点明显,可以稍微提高一点
- 感觉还是不太会写评测机,希望可以多多教教
8 reference
首先关于如何找到这些优秀的博客,相信大家通过co的学习已经积累了几位优秀的博主(暂且这么称呼罢),这几位学长的oo博客也非常的好。同时,通过在博客的主页中的友链中可以去发现一些其他友链,这大体上可以把这个往届六系成员组成的图的一个最大的生成子图(离散乱入)
https://volcaxiao.top/2023/02/28/BUAA-OO-Expr-expansion-1-0/
- 虽然这个网址不安全,但是也只有这个不安全啊!精品!
- 学长比较喜欢画
uml类图,可以仔细查看类图基本上可以知道整体的架构
https://hyggge.github.io/2022/03/24/oo/oo-di-yi-dan-yuan-zong-jie/
- 内容非常简洁,可以直接看出实现
- 同时对于一些大家可能都会遇到的细节处理上的难题也会提到,即使架构与学长不相同也可以参考阅读
https://thysrael.github.io/posts/8da51baf/
按照六系的某些奇奇怪怪的祖辈关系,这位学长都得算我的祖宗辈了- 文字非常详细的分析的自己的架构以及思路来源
- 而且能够看出来学长在写之前是没有参考太多的资料的,所以大部分都是学长自己的思考,根据和理由也非常充分

