Lab4实验报告
思考题
Thinking 4.1
思考并回答下面的问题:
- 内核在保存现场的时候是如何避免破坏通用寄存器的?
- 系统陷入内核调用后可以直接从当时的 $a0-$a3 参数寄存器中得到用户调用 msyscall留下的信息吗?
- 我们是怎么做到让 sys 开头的函数“认为”我们提供了和用户调用 msyscall 时同样的参数的?
- 内核处理系统调用的过程对 Trapframe 做了哪些更改?这种修改对应的用户态的变化是什么?
-
对于第一个问题,内核为了保存CP0寄存器中的信息,用到k0,在mips中规定了这几个寄存器只能由内核使用,所以我们在保存的时候是用到了k0。将CP0寄存器中的信息保存完后,马上将各个通用寄存器的值压栈。
-
能。在调用msyscall后马上进入syscall,syscall是mips中的指令
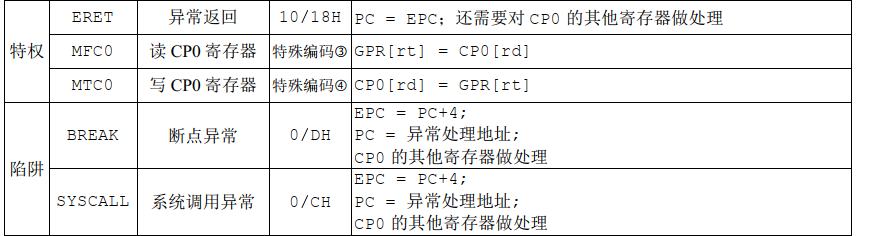
这里找到了计组的内容,也就是这里并没有对通用寄存器进行改变。
cpu跳转到指定位置后开始执行
do_syscall,这里是怎么跳转过来的呢800234b4 <handle_sys>: handle_sys(): /home/git/22373058/kern/genex.S:35 800234b4: 03a02025 move a0,sp 800234b8: 27bdfff8 addiu sp,sp,-8 800234bc: 0c0099e4 jal 80026790 <do_syscall> 800234c0: 00000000 nop 800234c4: 27bd0008 addiu sp,sp,8 800234c8: 08008cf0 j 800233c0 <ret_from_exception> 800234cc: 00000000 nop通过查看一个
objdump的信息就可以知道,因此在进入do_syscall之前将$sp的信息保存在了$a0中。进入
do_syscall后就是我们看到的样子,显而易见也没有改变通用寄存器的值,那么当然可以在陷入内核后调用msyscall留下的信息! -
在
do_syscall中对相应的参数(至多五个)进行了保存。然后作为函数参数传递给sys_* -
对
Trapframe的更改应该就是修改了tf->cp0_epc,增加了一个字的大小,同时修改了tf-reg[2],也就是tf中对应$v0这个寄存器的值。然后在执行完毕后会将各个寄存器的值恢复,那么$v0的值也会对应发生改变。
Thinking 4.2
思考 envid2env 函数: 为什么 envid2env 中需要判断 e->env_id != envid的情况?如果没有这步判断会发生什么情况?
显然,会出现一个进程,虽然是在envs里面的对应位置取的,但是它的envid和envid不一样。
我觉得主要可能会出现当前环境不在有效,那么对这个进程的操作都将是不合法的操作。同时也有可能会有并发的情况修改了envid。
Thinking 4.3
思考下面的问题,并对这个问题谈谈你的理解:请回顾 kern/env.c 文件中 mkenvid() 函数的实现,该函数不会返回 0,请结合系统调用和 IPC 部分的实现与envid2env() 函数的行为进行解释。
在mips中认为envid=0表示的是当前进程。因此在创建一个新的进程是如果envid=0,那么就无法区分新进程与当前进程。
此外这里需要把envid=0的进程和0号进程区分一下。
0号进程通常是内核进程,这个进程是系统初始化时创建的第一个进程,也被称为"init"进程的父进程。0号进程并不执行任何实际的程序代码,它的主要作用是作为进程调度器的一部分,参与进程的切换和调度的管理。在Linux系统中,这个进程通常用PID为0的进程表示,也被称为系统的“交换进程”。
在envid2env中,如果envid=0,会直接返回当前进程。
再看一下is_illegal_va中的实现,这个是基于是用户进程的基础上判断是否在用户空间[UTOP, UTEMP)这个区间。
Thinking 4.4
关于 fork 函数的两个返回值,下面说法正确的是:
A、 fork 在父进程中被调用两次,产生两个返回值
B、 fork 在两个进程中分别被调用一次,产生两个不同的返回值
C、 fork 只在父进程中被调用了一次,在两个进程中各产生一个返回值
D、 fork 只在子进程中被调用了一次,在两个进程中各产生一个返回值
C。
可以这么想,本来就只有父进程,所以调用肯定是他来调用。然后调用之后出现了子进程,子进程中也会有一个返回值。
Thinking 4.5
我们并不应该对所有的用户空间页都使用 duppage 进行映射。那么究竟哪些用户空间页应该映射,哪些不应该呢?请结合 kern/env.c 中 env_init 函数进行的页面映射、 include/mmu.h 里的内存布局图以及本章的后续描述进行思考。
从内存分布的角度来说,根据不同页面的作用,用户空间是UTEMP到UTOP之间的区域。其中UXSTACKTOP之上是每一段进程都有一个属于自己的,因此不需要共享映射。
然后剩下的其实理论上都可以映射。
Thinking 4.6
在遍历地址空间存取页表项时你需要使用到 vpd 和 vpt 这两个指针,请参考 user/include/lib.h 中的相关定义,思考并回答这几个问题:
- vpt 和 vpd 的作用是什么?怎样使用它们?
- 从实现的角度谈一下为什么进程能够通过这种方式来存取自身的页表?
- 它们是如何体现自映射设计的?
- 进程能够通过这种方式来修改自己的页表项吗
vpt和vpd分别是页表和页目录的首地址的指针。直接通过指针的方式使用,通过添加相应的值达到指定的页表项或页目录项。
第二问题的从实现的角度我没有特别懂。
#define vpt ((const volatile Pte *)UVPT)
#define vpd ((const volatile Pde *)(UVPT + (PDX(UVPT) << PGSHIFT)))或许是想表达每个进程有自己的用户空间,每个用户空间的特定位置存放着页表。因此可以通过固定的位置来访问页表和页表项。
自映射设计通过查看定义也能明白。页目录本质也是一个页表项,也是页表的一部分。自映射指的是“页目录中有一个页表项映射到了页目录本身”。页目录中每一项指示页表中的一项,这里是一一对应的关系,而恰好有一个页表项就是页目录,因此必然存在页目录中的某一项映射到的是页目录这个页表项。
在env_init的时候,没有设置PTE_D权限。会触发异常,通过内核态才能修改。
Thinking 4.7
在 do_tlb_mod 函数中,你可能注意到了一个向异常处理栈复制 Trapframe运行现场的过程,请思考并回答这几个问题:
这里实现了一个支持类似于“异常重入”的机制,而在什么时候会出现这种“异常重入”?
内核为什么需要将异常的现场 Trapframe 复制到用户空间?
异常重入机制的主要作用是允许操作系统在处理一个异常的同时,能够响应并处理其他异常。这种机制可以避免在处理一个异常时,系统被另一个异常中断,导致系统崩溃或数据丢失。
在do_tlb_mod中还需要写入页面,如果写入页面时出现异常,也就是页面不可写或者为写时复制页面的情况下会再次触发异常。
内核将异常现场保存到用户空间是为了用户处理异常时抛出另外一个异常,此时另外一个异常处理完成后可以通过自己用户空间的异常处理栈来恢复现场。
Thinking 4.8
在用户态处理页写入异常,相比于在内核态处理有什么优势?
- 符合微内核设计,使得内核的设计更加小巧。
- 用户与用户间相互独立,不互相影响,如果某个进程对于tlb的处理出现问题不会影响其他用户
- 提高性能,减少额外的上下文切换
Thinking 4.9
请思考并回答以下几个问题:
- 为什么需要将 syscall_set_tlb_mod_entry 的调用放置在 syscall_exofork 之前?
- 如果放置在写时复制保护机制完成之后会有怎样的效果?
需要在子进程创建前创立好子进程需要的环境,比如这里是为子进程准备好遇到tlb_mod异常的入口。
写时复制保护机制需要需要调用syscall_mem_map,如果此时出现缺页异常不能够及时响应。
难点分析
本次实验的难点主要在于fork函数的不好理解。同时还有如何在用户进程来处理本应该在内核中处理的程序,来符合微内核程序的设计。
IPC
这里的ipc只是两个进程之间进行阻塞式通信,因此实现起来相对比较简单,处理好异常情况即可。
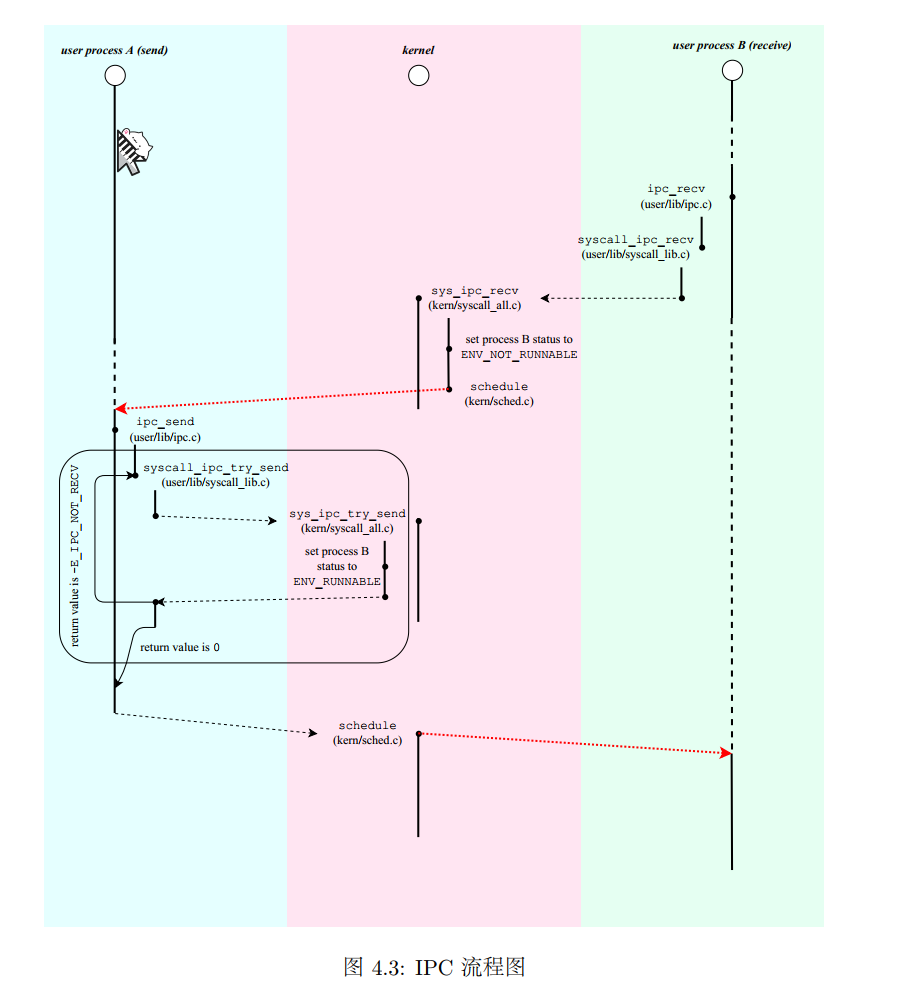
设置好接收方的相应env的信息后,来到发送方进行处理。
同时这里的共享内存用到了内核中的公共的区域,同时用到了页映射机制。
进程间通信
进程间通信机制是微内核最重要的机制之一。微内核设计主张将操作系统中的设备驱动、文件系统等可在用户空间实现的功能,移出内核,作为普通的用户程序来实现。
这样,即使他们崩溃也不会影响整个系统的稳定。
其他应用程序之间通过进程间通信来请求文件系统等相关服务。
- IPC的目的是使两个进程可以通信
- IPC需要通过系统调用来实现
- IPC还与进程的数据、页面等信息有关
这里可能会好奇把相关功能移出内核了,为什么IPC还会用到系统调用呢?
这里其实是相当于操作系统启动后,会自动开启几个用户进程,用于设备驱动和文件系统等(似乎叫做守护进程daemon),其他用户进程需要与这几个进程进行通信。
通信,MPI_send,MPI_receive这些,可以知道,通信其实就是数据的传递。
由于每个进程的地址空间是连续的,要想传递数据,我们就需要想办法把一个地址空间的东西传递给另一个地址空间。
这里就需要用到所有进程共享的内核空间主要是kseg0。因此交换数据可以通过内核空间来进行交换。send进程将数据以系统调用的形式存放在进程控制块中,接收方以系统调用的方式在进程控制块中找到对应的数据(在struct Env可以看到),读取并返回。
这里需要注意是从env_sched_list中移除。
env_sched_list是一个TAILQ,尾插队列,env_free_list是一个List双向链表。
需要注意。
recv进程的话简单,直接阻塞就行了,设置为not_runnable,移出调度队列。
send的话也不难,看对方有没有在准备接收,然后通过envid找到进程e,然后把信息传过去,并把e回复runnale,插入调度队列尾部。
但是最后的srcva对应的页映射到dstva。
这里我的处理是直接调用sys_mem_map()
try(sys_mem_map(curenv->env_id, srcva, e->env_id, e->env_ipc_dstva, perm));Fork()函数
fork函数设计多个函数,相互之间互相牵连,牵一发而动全身。
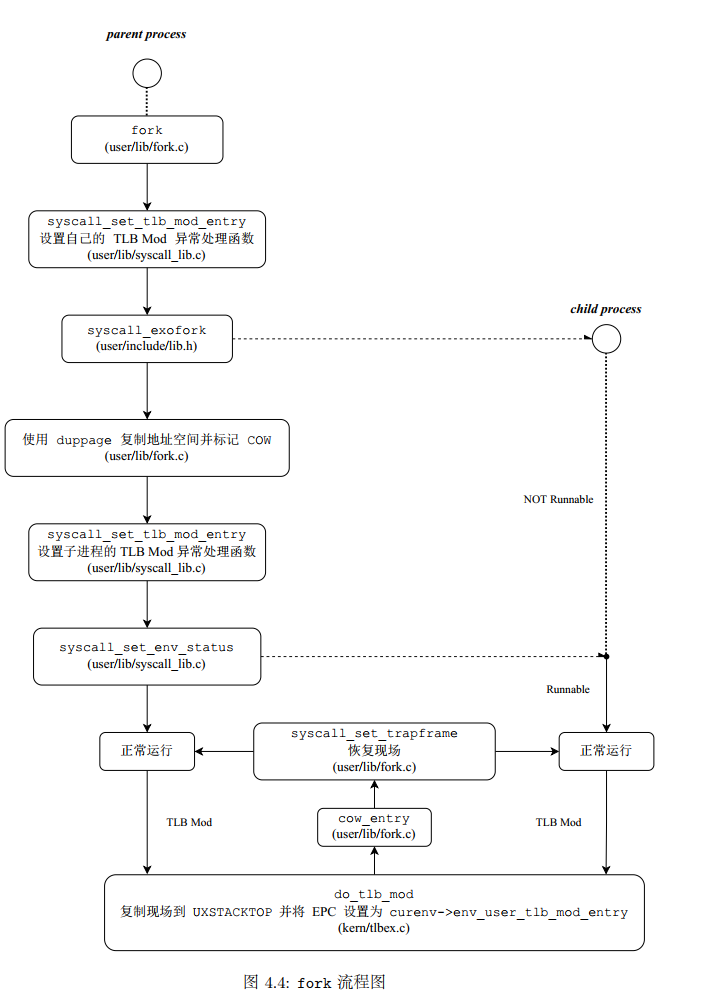
流程图往往是体现一个函数的调用关系的一个很好的东西。
内核通过env_create创建一个进程,进程创建一个进程就需要用到fork了,也相当于是内核提供给用户进程的一个接口,肯定也是要通过系统调用来得到的。
fork()在这个mos 里面的实现的流程:
-
kern/syscall_all.c系统调用中需要用到
-
kern/tlbex.c 完成写时复制前的相关设置
-
user/lib/fork.c 重点函数。需要处理写时复制
-
user/lib/entry.S 用户进程的入口
-
user/lib/libos.c 用户进程入口的C语言部分
-
kern/genex.S MOS的异常处理流程
-
写时复制
Copy On Write COW
写时复制的目的:减少物理内存的使用,比如代码段的内存是不需要复制的
写时复制的概述:在fork时,只需要将所有可写页面标记为写时复制页面,如果父子进程对这个有写入的操作时,会产生一种异常。
操作系统在异常处理的时候会为当前进程师徒写入的虚拟地址分配新的物理页面,并复制原页面的内容(注意这里与地址映射的区别),最后再返回用户程序,对新分配的物理页面进行写入。
这样从用户进程的角度就是我在写入指令发出后,还是得到了一块新的内存。
但是这里的地址都是虚拟地址,所以用户其实甚至不知道有了一块新的物理页面。
不得不说,虚拟空间真是一个好东西
这里需要用到硬件异常来实现。
进程通过tlb访问页面。如果tlb项没有设置PTE_D也就是dirty位,那么说明这个是只写的。如果需要写入,会触发TLB Mod(modification)修改异常。
可以在内核中设置相应的异常处理函数,来实现写时复制。
为了区分只读和写时复制,从tlb的角度来说,只有一个PTE_D位是不够的。所以需要添加一个PTE_COW位,来进行标志。
具体的异常处理函数就是,分配一页新的物理页,然后将写时复制页面的内容拷贝的只有个物理页,然后将这个物理页映射给正在写入这个写时复制页的进程。
当然,这里需要修改tlb的对应项的值。
所以,在fork的时候,需要先将所有的可写入的内存页面设置页表项标志位PTE_COW并取消可写位PTE_D。
从进程的角度来看,就是老老实实的操作内存,爽👍:happy:
fork函数的实现中,主要的系统调用是syscall_exofork,执行fork指令。
fork后得到了两个进程,两个几乎处于相同的运行状态的父子进程。可以认为在返回用户态的时候,父子进程都经历了同样的回复现场的过程。
父进程是从系统调用中返回时恢复现场,而子进程是进程被调度时会恢复现场,在现场恢复后,父子进程都会从内核返回到msyscall函数中,而它们在现场中存储的返回值是不同的,以作区分。
再次印证了我调用一个会返回的函数,第一步肯定是检查返回值,而不是去用里面的值。
实验体会
我觉得本次实验比lab3难多了,主要在于工作量更大了,更大的工作量会延长我的工作周期,导致前后写的时间会拉长很多。
一方面是到后期对于前期内容的遗忘,另一方面前期的内容的理解依赖后期,这使得我不得不之后再次进行一次复习。
同时这里还是得表扬一下os的填空题的特性,可以帮助我们更好的填出需要填充的代码,降低了学习的难度。但是仅仅只是利用提示来写,肯定还是不行,了解全局调用的流程,同时不时查看其他操作系统的处理,能够帮助我们更好的理解这些东西。
真的好难啊!!😢😢

