lab4
实验目的:
- 掌握系统调用的概念及流程
- 实现进程间通信机制
- 实现fork函数
- 掌握页写入异常的处理流程
系统调用:
这个东西早有耳闻。在用户态下,用户进程不能访问系统的内核空间,也不能调用内核函数,这一点是由体系结构保证的。然后用户进程在特定的场景下往往需要执行一些只能由内核完成的操作,如硬件操作、动态分配内存,以及与其他进程进行通信等。
而允许内核态执行用户程序提供的代码显然是不安全的,因此操作系统设计了一系列内核空间中的函数,当用户进程需要进行这些操作是,会引发特定的异常以陷入内核态,有内核调用对应的函数,从而安全地为用户进程提供受限的系统级操作,这种机制就是叫做系统调用。
这里解释一下,用户程序代码的不安全应该不是指会进行一些rm -rf /*这种操作,这个是无法避免的,应该指的是用户的程序被内核态执行,相当于一个普通用户的代码给sudo用户执行,可能会把其他用户给删了这种危险的操作,而提供几个接口也限制了用户调用系统内核的能力。
用户态和内核态:CP0 SR寄存器中的UM位和EXL位决定。是cpu硬件决定的
用户空间和内核空间:kuseg kseg0&kseg1
用户进程和内核:二者并不是对立的存在,可以认为内核是村子啊与所有进程地址空间的一段代码,内核负责管理系统资源和调度进程,是进程能够并发执行。
系统调用:比如syscall就是一种系统调用指令,是的进程陷入到内核的异常处理程序中。
这里讲道了应用程序编程接口API,比如c里面的printf就是其中一种,实际上是包装了系统调用的底层实现比如write(write的实现又是调用了syscall这种,在mips里面)等。
系统调用机制的实现
系统调用的本质就是进入内核态执行相应的操作,只是说内核态提供的接口让你只能做这几种操作。
有一个有意思的例子就是,你家长只是给你钱让你去买棒棒糖等,但是不是完全把钱给你,随你处置。类似这个吧(
lab3中的中断异常处理:
- 处理器跳转到异常分发代码处。
- 进入异常分发程序,根据cause寄存器的值判断异常类型并跳转到对应的处理程序
- 处理异常,返回
坏了,都不记得了
原来lab3的重点是这个,我倒是没意识到哈~
tlb异常倒是看到了,时钟中断在哪里哇。??
debugf.c
- 将参数解析为字符串 & 将字符串输出(
debug_output) debug_output中的debug_flush调用syscall_print_cons函数,又调用msyscall函数,当我们继续找msyscall又调用了哪个函数的时候,在usr/lib/syscall_wrap.S中找到了Exercise 4.1,樂msyscall的调用,使得系统陷入了内核态- 内核态中将异常分发到
handle_sys函数,将系统调用所需要的信息(相当于传参,但是我感觉更像进程通信,这里是需要输出的字符串s)传入内核 - 内核取得信息,执行相应的内核空间的系统调用函数
sys_*,这一些函数在kern/syscall_call.c中 - 系统调用完成,并返回内核态,同时将返回值传递会用户态
- 从系统调用函数返回,回到用户程序的debugf调用处。
我觉得这个确实把系统调用讲得很清楚了。
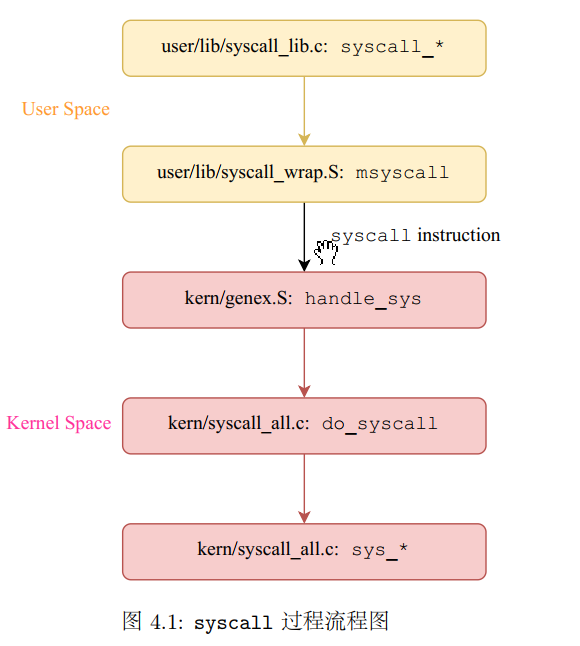
从这个来看,最接近内核的函数是sysycall_*,在内核中 的sys_*则是对应的实现,但是已经进入了内核态。
syscall_*都调用了msyscall这个函数,第一个都是与调用名相似的宏SYS_print_cons,这个是系统调用号。至于这个是干嘛用的呢,相当于是用来区分不同的调用类型的,从进程间通信的角度(我觉得这里还是更像传参x),如果不把这个信息传递给内核,内核是不知道具体是哪一种系统调用的。因为毕竟syscall_*都是调用的msyscall这同一个函数,因此需要多一个参数进行区分。
调用了之后就进入到了汇编语言部分。
那么在汇编语言部分如何获取传入的参数呢,理论上只要存到了内存里,你告诉我怎么去拿都是可以的,所以这里就是mips的调用规范,mips用到的是通过压栈和出栈来进行函数调用!
4.1就是直接用syscall就行了,因为参数那些有mips规范已经帮你存好了,你只需要用的时候知道在哪就行了,msyscall作为一个中间者,不需要知道这个。
syscall是一个mips的一个指令,是通过硬件实现进入内核态的。详情参见计组!
在计组里面我们知道,调用中断指令后,cpu的pc会在保存现场后跳转到指定位置。
虽然不知道怎么就到了do_syscall这个函数。
现在知道了!还是得靠
objdump啊
基础系统调用函数
接下来需要实现几个系统调用
sys_mem_alloc,这个函数的功能主要是分配内存,用户程序可以通过这个系统调用给该程序所运行的虚拟内存空间显式地分配实际的物理内存。
从程序员的视角而言,是程序在内存中申请了一片空间。
对于操作系统内核而言,实际上是一个进程请求将其虚拟空间中的某一段地址和实际的物理地址进行 一个映射,从而可以通过虚拟页面对这个物理页面进行访问。
这里并没有提高后续访问的操作,后续访问中应该还需要处理如果有写入等时,关于写时复制等操作。
e = &envs[ENVX(envid)];
// e = envs + ENVS(envid);上面是我写的,下面是学长写的,众所周知,这两个是一样的,但是明显学长的更简洁,为什么,因为a[i]=*(a+i)
int re = envid2env(envid, &env, perm);
if (re != 0)
return -E_BAD_ENV;
if(envid2env(envid,&env,1)<0){
return -E_BAD_ENV;
}上面是我的,下面是学长的,一样的!
sys_mem_map:将源地址空间中的相应内存映射到目标进程的虚拟空间的内存中。这里相当于是有两个或者多个进程共享同一块物理内存。但是这一块物理内存被分配到了不同进程的虚拟内存中。
这里传入的参数是src和dst的envid。那么大致的操作流程就是
- 首先找到两个进程
- 从src的虚拟页面找到对应的物理页面
- 将物理页面与dst的虚拟页面进行映射
这里的page_lookup我纠结了很久这里的ppte应该是什么,甚至写出了这种鬼东西Pte* p = (Pte*)KADDR(PTE_ADDR(pgdir));
查看了page_lookup的代码发现。
这个代码主要还是找到哪一个在哪一个页目录中,对是哪一个页表其实没那么关心。
这都要怪lab2啥都没搞懂,现在还是不太懂。
那么这里就分析一下这个吧:
这个的目的是通过Pde和va、ppte找到相应的页面。按照多级页表,首先需要在页目录中找到是在哪一个页表项(这个可以直接根据va得到)。
那么page_lookup里面首先调用了page_walk
看page_walk的描述可以知道,这个函数的作用是,通过给定的一个页目录的入口,找到这个虚拟地址va对应的页表入口。
看看page_walk的具体实现。首先是得到这个虚拟地址相应的页目录的地址。是从pgdir的基础上,增加PDX(va)得到的。
这个是为什么呢
如果这个页面不合法,那么根据是否create来决定是page_alloc一个页面,然后将返回的页面的物理地址赋值给pgdir_entryp,也就是得到一个新的页面对应的实际物理页目录的地址。
可以看到我们这里是没有create的。
那么在哪里需要create呢,在
page_insert那里需要。
然后通过这个页目录入口可以得到ppte的基地址(其实也就是将后面12位赋0后对应到内核地址),然后加上va的页表项偏移。
就得到了pte。
现在得到了页表项,实际上就可以马上得到页面了。访问一下这个页表的值就可以了。
根据页表自映射,这个页表项对应的页在所有页面中的地址为pa>>12,也就是pages的第这个项。
至于最后ppte的作用会发现就是一个赋值的作用。如果这个东西不是NULL,那就给它赋值为在pgdir_walk中得到的pte。
关键作用还是得到Page* pp。
好难啊!
所以根据分析,这里的pte直接用NULL就行了。
sys_mem_unmap,这个调用的功能是解除某个进程地址空间虚拟地址和物理地址的映射关系。相当于在那个进程的虚拟空间中删去这个页面。
这里还是很简单的。
但是要考虑一点。这里没有提供perm,那么我们就来分析一下在envid2env中perm的作用来决定具体取什么值。
这个在struct Env这个结构体中可以知道这个指的是权限位。也就是设置了权限后需要进行额外的检查。那么这里不需要进行检查,那就直接设置为0就好了。
这个其实牵涉到后面的fork中的父子进程的关系。由于我是一边写思考一边写作业,后面还没写,具体情况稍后再看
sys_yield:这个函数调用的功能是实现用户进程对CPU的放弃,从而调度其他进程。这个直接调用schedule,但是还需要传一个参数,看一下全局的调用,发现要么填0,要么填1。可以直接根据这个参数的名称yield来判断,直接上去一个1,搞定。
咱再来具体分析一下。
进入到schedule可以发现,如果是yield,会直接吧这个进程ban掉(remove),然后再调度一个。所以显然schedule(1)
IPC
进程间通信
进程间通信机制是微内核最重要的机制之一。微内核设计主张将操作系统中的设备驱动、文件系统等可在用户空间实现的功能,移出内核,作为普通的用户程序来实现。
这样,即使他们崩溃也不会影响整个系统的稳定。
其他应用程序之间通过进程间通信来请求文件系统等相关服务。
- IPC的目的是使两个进程可以通信
- IPC需要通过系统调用来实现
- IPC还与进程的数据、页面等信息有关
这里可能会好奇把相关功能移出内核了,为什么IPC还会用到系统调用呢?
这里其实是相当于操作系统启动后,会自动开启几个用户进程,用于设备驱动和文件系统等(似乎叫做守护进程daemon),其他用户进程需要与这几个进程进行通信。
通信,MPI_send,MPI_receive这些,可以知道,通信其实就是数据的传递。
由于每个进程的地址空间是连续的,要想传递数据,我们就需要想办法把一个地址空间的东西传递给另一个地址空间。
这里就需要用到所有进程共享的内核空间主要是kseg0。因此交换数据可以通过内核空间来进行交换。send进程将数据以系统调用的形式存放在进程控制块中,接收方以系统调用的方式在进程控制块中找到对应的数据(在struct Env可以看到),读取并返回。
这里需要注意是从env_sched_list中移除。
env_sched_list是一个TAILQ,尾插队列,env_free_list是一个List双向链表。
需要注意。
recv进程的话简单,直接阻塞就行了,设置为not_runnable,移出调度队列。
send的话也不难,看对方有没有在准备接收,然后通过envid找到进程e,然后把信息传过去,并把e回复runnale,插入调度队列尾部。
但是最后的srcva对应的页映射到dstva。
这里我的处理是直接调用sys_mem_map()
try(sys_mem_map(curenv->env_id, srcva, e->env_id, e->env_ipc_dstva, perm));但是我看学长们的处理是:
p = page_lookup(curenv->env_pgdir, srcva, NULL);
if (p == NULL)
return E_INVAL;
try(page_insert(e->env_pgdir, e->env_asid, p, e->env_ipc_dstva, perm));我觉得是一样的。。。
TODO:晚点测一下
倒是我这个确实多了一步,还从id到env,这里直接有env了。
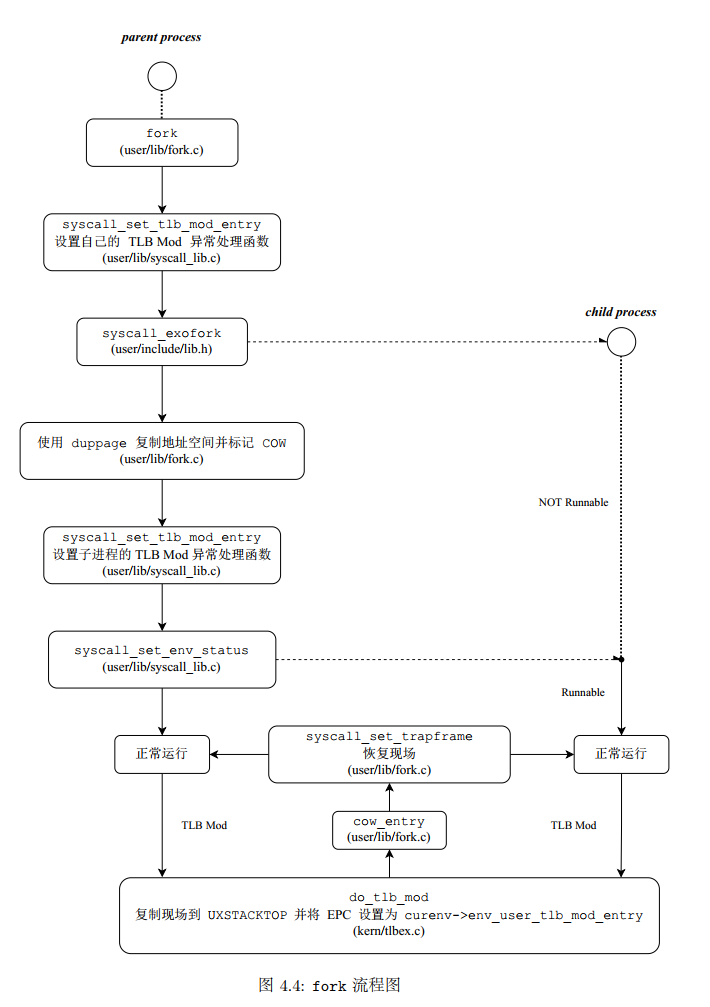
Fork
内核通过env_create创建一个进程,进程创建一个进程就需要用到fork了,也相当于是内核提供给用户进程的一个接口,肯定也是要通过系统调用来得到的。
fork()在这个mos 里面的实现的流程:
- kern/syscall_all.c系统调用中需要用到
- kern/tlbex.c 完成写时复制前的相关设置
- user/lib/fork.c 重点函数。需要处理写时复制
- user/lib/entry.S 用户进程的入口
- user/lib/libos.c 用户进程入口的C语言部分
- kern/genex.S MOS的异常处理流程
- 写时复制
Copy On Write COW
写时复制的目的:减少物理内存的使用,比如代码段的内存是不需要复制的
写时复制的概述:在fork时,只需要将所有可写页面标记为写时复制页面,如果父子进程对这个有写入的操作时,会产生一种异常。
操作系统在异常处理的时候会为当前进程师徒写入的虚拟地址分配新的物理页面,并复制原页面的内容(注意这里与地址映射的区别),最后再返回用户程序,对新分配的物理页面进行写入。
这样从用户进程的角度就是我在写入指令发出后,还是得到了一块新的内存。
但是这里的地址都是虚拟地址,所以用户其实甚至不知道有了一块新的物理页面。
不得不说,虚拟空间真是一个好东西
这里需要用到硬件异常来实现。
进程通过tlb访问页面。如果tlb项没有设置PTE_D也就是dirty位,那么说明这个是只写的。如果需要写入,会触发TLB Mod(modification)修改异常。
可以在内核中设置相应的异常处理函数,来实现写时复制。
为了区分只读和写时复制,从tlb的角度来说,只有一个PTE_D位是不够的。所以需要添加一个PTE_COW位,来进行标志。
具体的异常处理函数就是,分配一页新的物理页,然后将写时复制页面的内容拷贝的只有个物理页,然后将这个物理页映射给正在写入这个写时复制页的进程。
当然,这里需要修改tlb的对应项的值。
所以,在fork的时候,需要先将所有的可写入的内存页面设置页表项标志位PTE_COW并取消可写位PTE_D。
从进程的角度来看,就是老老实实的操作内存,爽👍:happy:
fork函数的实现中,主要的系统调用是syscall_exofork,执行fork指令。
fork后得到了两个进程,两个几乎处于相同的运行状态的父子进程。可以认为在返回用户态的时候,父子进程都经历了同样的回复现场的过程。
父进程是从系统调用中返回时恢复现场,而子进程是进程被调度时会恢复现场,在现场恢复后,父子进程都会从内核返回到msyscall函数中,而它们在现场中存储的返回值是不同的,以作区分。
再次印证了我调用一个会返回的函数,第一步肯定是检查返回值,而不是去用里面的值。
sys_exofork:
- 运行现场:复制一份当前的运行线程tf到子进程的env中
- 返回值:应该在系统调用的envid只传递给父进程,将自己称线程中的
$v0修改为0 - 进程状态:在
syscall_exofork后,子进程不能马上被调度。 - 其他信息,对相应字段进行初始化
这里的复制现场这里
我是这么写的:
e->env_tf = *((struct Trapframe*)KSTACKTOP - 1);由于应该是复制,那这么写肯定是有失妥当的,但是我看到yyt学长也是这么写的
???纳闷
正确的应该使用memcpy进行复制
memcpy((void*)&(e->env_tf), (void*)(KSTACKTOP - sizeof(struct Trapframe)), sizeof(struct Trapframe));结构体的赋值,是直接结构体的内存的拷贝
神奇的C语言,所以两种都可以
在用户进程的入口usr/lib/entry.S中会跳转到limain中,这里面刚开始就是一个系统调用syscall_genenvid。也即是说,每一个用户进程在运行时的入口这里将一个用户空间的struct Env *env指向当前进程的控制块。
对于fork后的子进程,它具有了一个随机分配的与父进程不同的struct Env,因此需要在子进程第一次被调度的时候,对这个env进行值的更新,同时它仍然指向当前进程。
??
更新env:
- 通过一个系统调用取得自己的envid
- 根据envid,计算对应进程控制块的下标,将对应的进程控制块的指针赋给env
父进程还需要将地址空间中需要与子进程共享的页面映射给子进程,需要遍历父进程的大部分用户空间页。
这里的大部分有点意思,也就是说不是所有的都需要复制。比如代码段就不需要复制。
这里是通过duppage来实现的。在父进程和子进程中都需要加入PTE_COW标志位,同时取消PTE_D标志位,实现写时复制保护。
这里tlb是有asid这个来区分不同的进程的,所以说是父子进程都需要!
duppage
这个暂时先不考虑某些页面可以不用遍历。
需要对不同页面的情况进行区分
- 只读页面:按照相同的权限映射给子进程
- 写时复制页面:是
fork时duppage的结果,且在本次fork之前必然未被写入过 - 共享页面:
PTE_LIBRARY,保持共享可写的状态,,在父子进程中映射到相同的物理页,双方对其的修改双方都可见。 - 可写页面:在父进程和子进程的页表项中都使用
PTE_COW进行保护
感觉页表还是不太懂😢
这里我是这么写的
// 这些页面应该是用户空间,也就是父进程的页面
// 在用户空间,他的id就是0
if ((perm | PTE_D) && !(perm | PTE_LIBRARY) && !(perm | PTE_COW)) {
// 可写入 不是共享页面 不是写时复制页面
perm = (perm & ~PTE_D) | PTE_COW; // 加入写时复制保护
syscall_mem_map(0, addr, envid, addr, perm); // 先复制给子进程
syscall_mem_map(0, addr, 0, addr, perm); // 然后复制给父进程
} else {
// 不可写页面 共享页面
syscall_mem_map(0, addr, envid, addr, perm); // 其他的该是什么权限就是什么权限
}有学长是这么写的
if((perm&PTE_D)&&!(perm&PTE_LIBRARY)&&!(perm&PTE_COW)){
syscall_mem_map(0,(void*)addr,envid,(void*)addr,(perm|PTE_COW)&(~PTE_D));
syscall_mem_map(0,(void*)addr,0,(void*)addr,(perm|PTE_COW)&(~PTE_D));
}
else{
syscall_mem_map(0,(void*)addr,envid,(void*)addr,perm);
}其实主要区别就是有没有在用户空间修改perm的值,这里当然可以修改啦。因为就是在父进程这里。需要保护自然会设置保护位。
- 页写入异常
TLB_Mod
如果出现对写时复制的页有写入的情况,那么就会触发这个异常。
然后这里很有意思,说在do_tlb_mod中没有进行页面复制等操作,然后说这个是为了按照微内核的设计理念,所以把页写入异常的处理放在用户态处理了。
感觉这个从设计上来说有点搞笑,但是从学习的角度还是合理的。为了让我们看看微内核下用户态如何处理一些本在内核中处理的操作。
- 异常处理栈
任何处理肯定都需要一个栈来处理参数这些。但是又不能使用用户原本的用户栈

所以就用了额外的一段空间用来作为异常处理栈。
处理页写入异常:
- 用户触发页写入异常,陷入内核的
handle_mod,然后跳转到do_tlb_mod函数 do_tlb_mod将当前现场保存在异常处理栈中,并设置好$a0 EPC的值,使得异常恢复后能够回到用户异常处理函数的地址- 从异常恢复到用户态
do_tlb_mod
一行的工作量,樂
往年题分析
2021-lab4-1-exam


这里task1是写写汇编,写写循环,压压栈。
task2主体部分抄抄正常的send,用好task1的东西
2021-lab4-1-extra

两次信息传递
在第一个进程结束后调度第二个进程
2021-lab4-2-exam
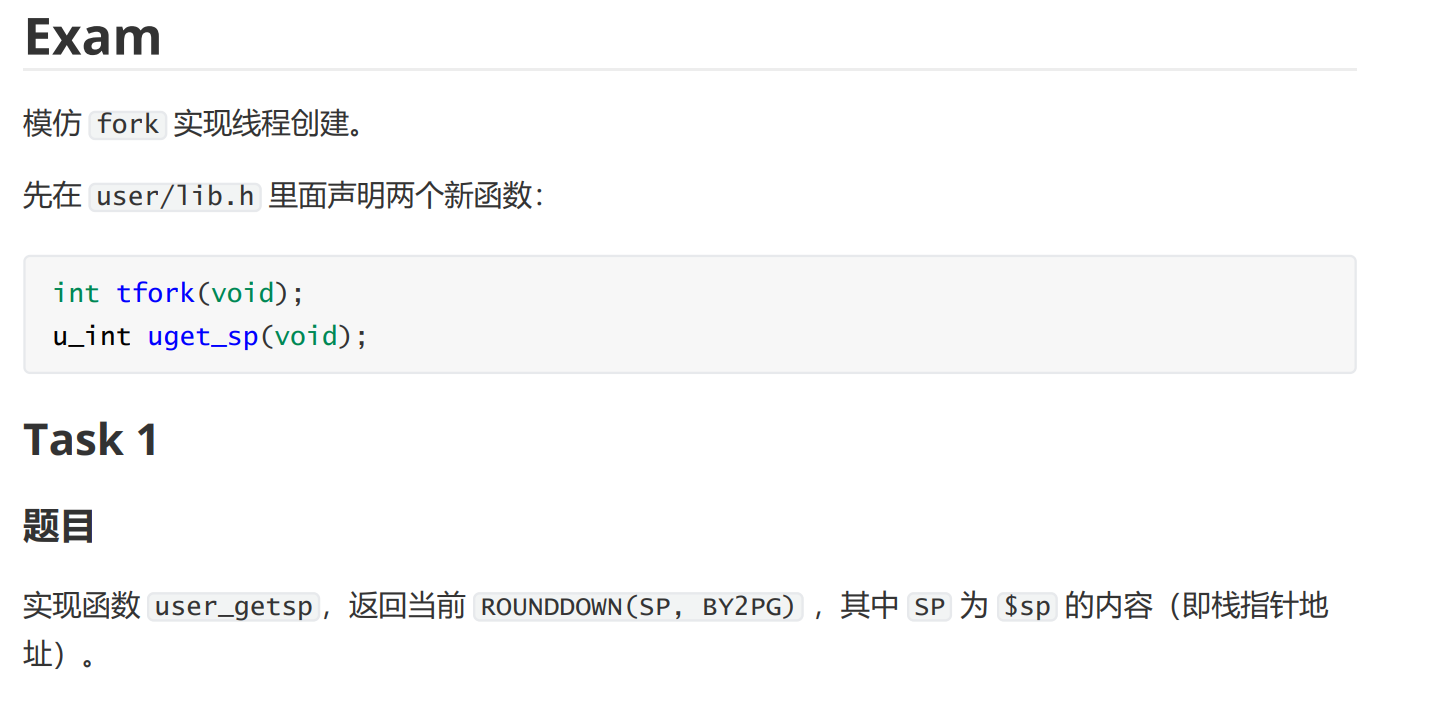

获取寄存器的内容需要通过汇编实现
// user/entry.S
.glbal uget_up
uget_up:
li v0, 0xffff_f000
and v0, v0, sp
jr ra
nop设置返回值使用v0即可
会发现与fork只有共享空间不同,修改duppage即可
2021-lab4-2-extra

2022-lab4-1-exam
https://github.com/rfhits/Operating-System-BUAA-2021/blob/main/4-lab4/上机.md

