Lab5实验报告
思考题
Thinking 5.1
如果通过 kseg0 读写设备,那么对于设备的写入会缓存到 Cache 中。这是一种错误的行为,在实际编写代码的时候这么做会引发不可预知的问题。请思考:这么做这会引发什么问题?对于不同种类的设备(如我们提到的串口设备和 IDE 磁盘)的操作会有差异吗?可以从缓存的性质和缓存更新的策略来考虑。
第一个原因:
这里的mips 4Kc cpu,在boot时,运行在kseg1中的bootloader会在载入内核前进行cache的初始化,同时我们知道bootloader会加载硬盘中的MBR等,这里就是在进行外设的读写,如果直接在kseg0,那这里的cache会由于没有初始化而出大问题。
但是考虑到可能有一些cpu是硬件自动完成cache的初始化,考虑第二个原因
第二个原因:
对于不同的缓存写策略,可能会出现cache中已经写入了,但是内存还没有修改,需要等待那个页面被替换然后写入(写回法),那么此时会出现数据不一致的问题,当外设对这一部分对应的内存访问是会出现问题。
对于磁盘不会有太大的影响,只是会导致写入的时机延迟。但是对于串口通信设备,当写入信息进入到内存时,由于cpu没有将相应的页写入cache中,不会及时访问,某一瞬间这一页被替换后会导致出现实时性的问题。
Thinking 5.2
查找代码中的相关定义,试回答一个磁盘块中最多能存储多少个文件控制块?一个目录下最多能有多少个文件?我们的文件系统支持的单个文件最大为多大?
- 一个磁盘块的大小为4096B=4KB,每个文件控制块为256B,因此一个磁盘块最多能存储$2^4=16$个文件控制块
- 一个目录下,最多占满1024个磁盘块,因此最多$1024\times 16=16384$个文件
- 支持的单个文件最大为一整个磁盘空间,也就是4MB
Thinking 5.3
请思考,在满足磁盘块缓存的设计的前提下,我们实验使用的内核支持的最大磁盘大小是多少?
块缓存所在的地址空间为[0x10000000, 0x4fffffff),因此我们的内核能够支持的磁盘大小为0x40000000,也就是1GB
Thinking 5.4
在本实验中, fs/serv.h、 user/include/fs.h 等文件中出现了许多宏定义,试列举你认为较为重要的宏定义,同时进行解释,并描述其主要应用之处。
比较重要的宏定义:
\#define DISKMAP 0x10000000,定义了磁盘在虚拟内存中映射的起始位置#define DISKMAX 0x40000000,定义了磁盘在虚拟内存的缓冲块的大小#define PTE_DIRTY 0x0004// file system block cache is dirty#define SECT_SIZE 512/* Bytes per disk sector */#define SECT2BLK (BLOCK_SIZE / SECT_SIZE)/* sectors to a block */#define BLOCK_SIZE PAGE_SIZE// 就是PAGE_SIZE 4096Byte 4KB#define BLOCK_SIZE_BIT (BLOCK_SIZE * 8)#define MAXNAMELEN 128,文件名的长度最大值#define NDIRECT 10,最多10个直接磁盘块#define FILE_STRUCT_SIZE 256,文件控制块的大小#define FILE2BLK (BLOCK_SIZE / sizeof(struct File)), // 也就是每一个块有多少个文件控制块,向下取整,这里是16
Thinking 5.5
在 Lab4“系统调用与 fork”的实验中我们实现了极为重要的 fork 函数。那么 fork 前后的父子进程是否会共享文件描述符和定位指针呢?请在完成上述练习的基础上编写一个程序进行验证。
这里fork的时候是将父进程的页表中映射部分地址到子进程,因此fork前后的父子进程会共享文件描述符和定位指针。
对于测试程序的主体是:
int id;
if ((id = fork()) == 0) {
struct Fd* fdd;
fd_lookup(r, &fdd);
debugf("child_fd's offset == %d\n", fdd->fd_offset);
} else {
struct Fd* fdd;
fd_lookup(r, &fdd);
debugf("father_fd's offset == %d\n", fdd->fd_offset);
}然后比较二者在FDTABLE的偏移是否相同即可,观察结果为二者相同,所以是同一个文件描述符。
Thinking 5.6
请解释 File, Fd, Filefd 结构体及其各个域的作用。比如各个结构体会在哪些过程中被使用,是否对应磁盘上的物理实体还是单纯的内存数据等。说明形式自定,要求简洁明了,可大致勾勒出文件系统数据结构与物理实体的对应关系与设计框架。
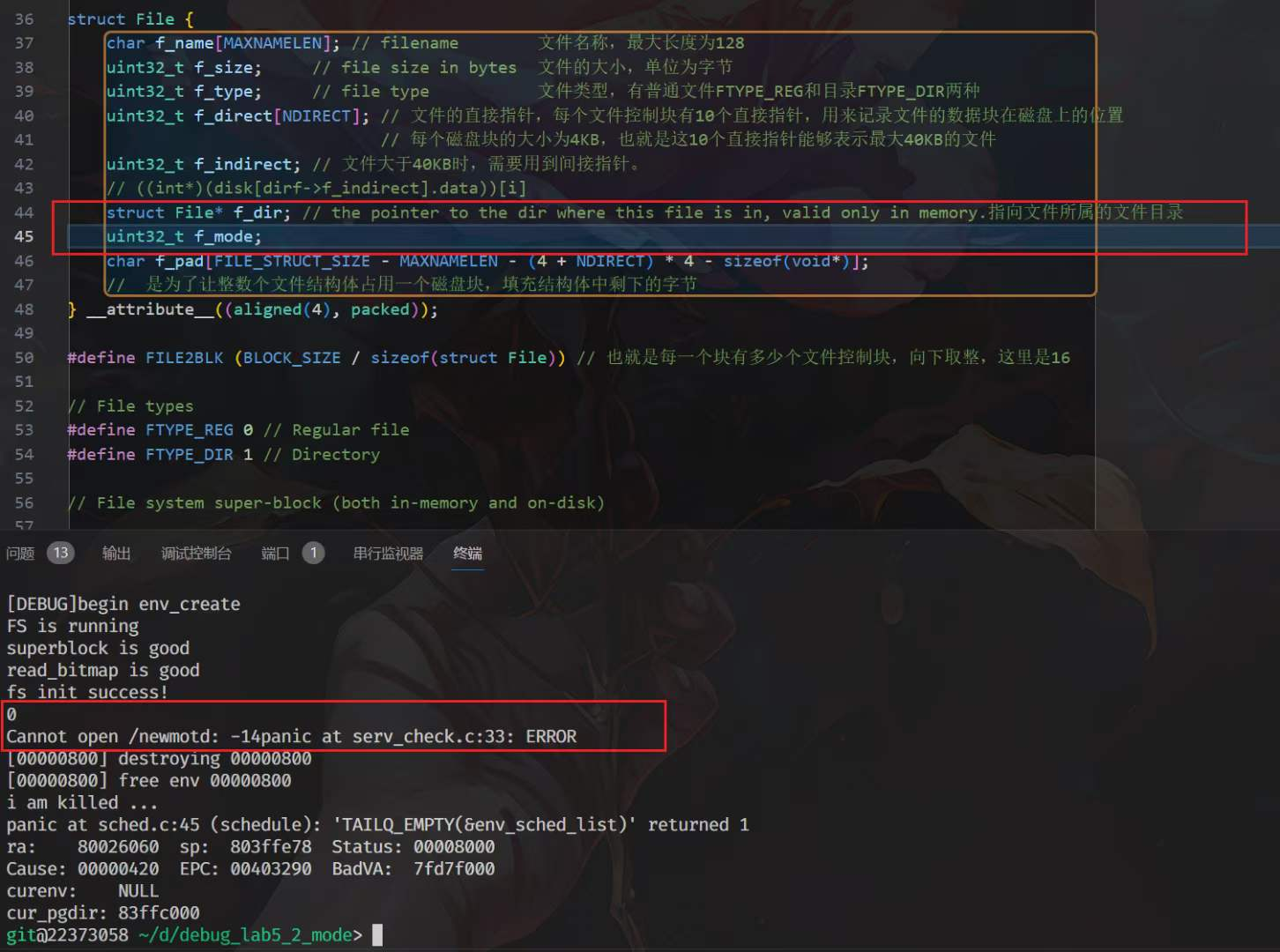
struct File {
char f_name[MAXNAMELEN]; // filename 文件名称,最大长度为128
uint32_t f_size; // file size in bytes 文件的大小,单位为字节
uint32_t f_type; // file type 文件类型,有普通文件FTYPE_REG和目录FTYPE_DIR两种
uint32_t f_direct[NDIRECT]; // 文件的直接指针,每个文件控制块有10个直接指针,用来记录文件的数据块在磁盘上的位置
// 每个磁盘块的大小为4KB,也就是这10个直接指针能够表示最大40KB的文件
uint32_t f_indirect; // 文件大于40KB时,需要用到间接指针。
// ((int*)(disk[dirf->f_indirect].data))[i]
struct File* f_dir; // the pointer to the dir where this file is in, valid only in memory.指向文件所属的文件目录
char f_pad[FILE_STRUCT_SIZE - MAXNAMELEN - (3 + NDIRECT) * 4 - sizeof(void*)];
// 是为了让整数个文件结构体占用一个磁盘块,填充结构体中剩下的字节
} __attribute__((aligned(4), packed));文件控制块是存放在磁盘上的物理实体,包含了文件的基本数据(元数据)
// file descriptor
struct Fd {
u_int fd_dev_id; // 外设的id
// 用户是用fd.c的用户接口是,不同的dev_id会调取不同的文件服务函数
// fd_dev_id的取值可以是devfile.dev_id "f" 或者是 devcons.dev_id "c"
u_int fd_offset; // 读写的偏移量
// 在file_read、file_write会改变这个偏移量
// 在seek()时也会修改
// offset会被用来找起始filebno文件块号。
u_int fd_omode; // 打开方式,包括只读、只写、读写
// serve_open是会进行修改,read和write时会用到
};Fd是用户使用的。也就是用来记录已经打开的文件的状态,便于用户直接使用文件描述符对文件进行操作、申请服务等。由于文件描述符主要是为用户所使用,因此是存放在内存上的数据。
// file descriptor + file
// 为了让Fd*类型的结构体可以存储更多信息,常常用来强转
struct Filefd {
struct Fd f_fd; // file descriptor 文件描述符
u_int f_fileid; // 文件的id
// 会用来索引opentab[]中对应的open控制块
struct File f_file; // 这个文件描述符对应的文件控制块
};Filefd 以及 fd 中的指向的文件控制块 File 中记录的磁盘指针对应物理实体。文件描述符常常能够表示的信息是有限的,需要将Fd*强制转换为Filefd*从而存储更多的文件信息
Thinking 5.7
图 5.9 中有多种不同形式的箭头,请解释这些不同箭头的差别,并思考我们的操作系统是如何实现对应类型的进程间通信的。
上面的三个箭头表示的是同步消息:是指消息的发送者将消息发送出去后,暂停活动,等待消息接收者的回应消息。这里是阻塞式的消息发送。
最下面那个ipc_send(dst_va)的是异步消息或者说返回消息,直接将消息发送出去,不进行等待也不需要知道返回值。
难点分析
这里主要是对于整体的把握非常困难,包括有很多的


这一章讲文件系统,其实核心是将外设device。正是由于一切皆文件,才能对外设有统一的管理,或者说为了对外设有统一的管理,于是诞生了一切皆文件的概念。这两个我不清楚哪个在前,一个是目的,一个是方法,或许是方法早就有,恰好对上了这个目的。
计算机底层的发展,好像是一部双向链表,在某一历史节点,这两个结点连在了一起。从此他们便是一个整体
- 实验目的
文件系统、磁盘、设备驱动、文件系统服务、微内核
谈到微内核呢,很有意思。鸿蒙os是微内核,linux是宏内核;目前来看,微内核好慢,宏内核还挺好。微内核慢是因为需要不断进行进程之间的通信,内核需要不断处理信息之间的传递,但是把不同服务程序提出去,在用户态执行,如果可以做到通信的速度进一步加快,每一个进程的独立性提高,不仅安全性这一微内核本身的优势还在,还有了更好的速度。
微内核这和网络中的TCP/IP协议很像,不同程序都先到底层进行数据传送,但是在多用户的时候这种计网中类似的结构就很快了,主要在于交换机技术是的能够不同的网络信息进行排队调度,使得或许的共享资源传送更加快速。
当然,还有一个有意思的,就是linux的宏内核设计使得对于类似安卓这种不希望将自己的东西开源的,会调用内核接口,然后在用户层实现,这倒是引起了开源社区的大大不满。但是如果最开始就是微内核,那就大大避免了这个问题,大胆想想,华为这是想当安卓界的linux啊。
文件系统,比如FAT、HPFS 和NTFS都是一种文件系统,似乎是不同的文件(磁盘)组织格式,各司其职,但是具体有什么用,我不懂。
首先将外设,一般会拿最经典的磁盘,至于打印机能不能有,也行,一次传输一个字符这种。磁盘作为空间的扩容,是内存的拓展,内存是磁盘的cache。文件系统是管理磁盘的工具。
广义上,一切带标识的、在逻辑上有完整意义的字节序列都可以称为“文件”。文件系统将外部设备中的资源抽象为文件,从而可以统一管理外部设备,实现对数据的存储、组织、访问和修改等操作。
- 文件系统总览图
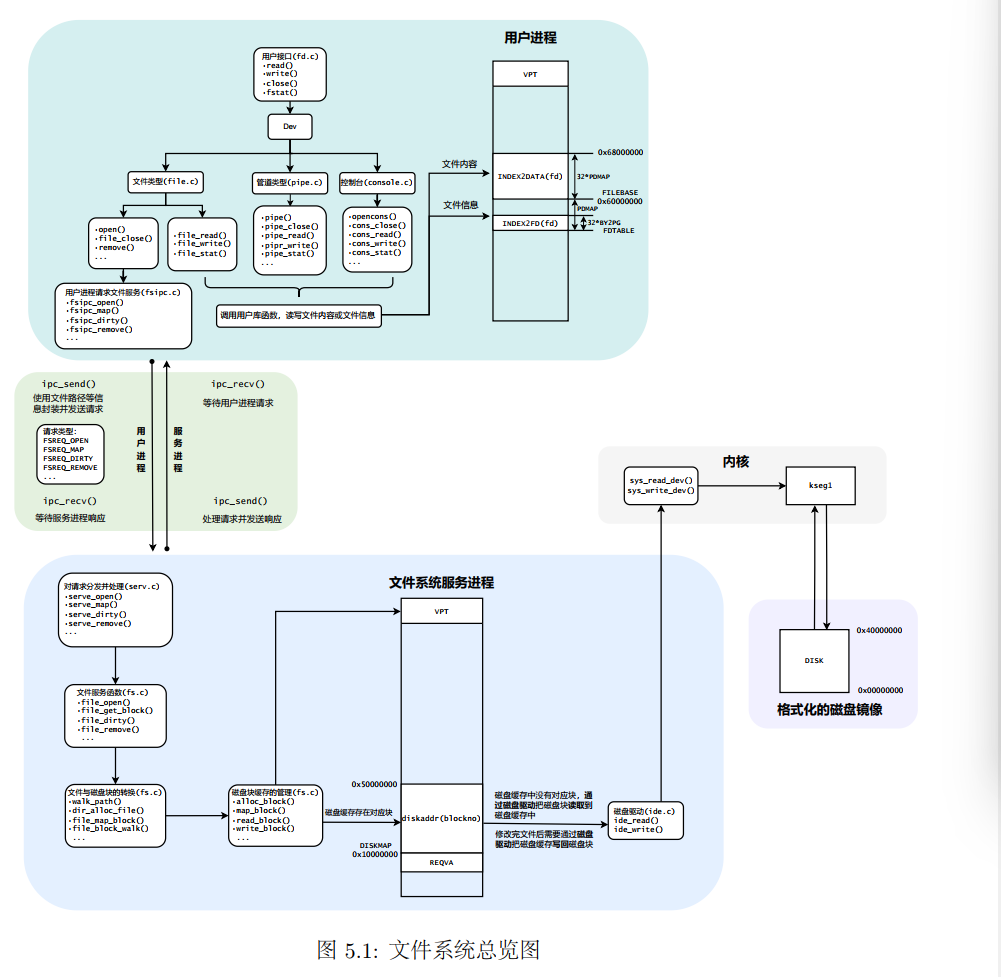
我们先啥都不看,就分析这张图
宏观上看,这里是微内核结构的完美体现。虽然我觉得lab4的由用户处理tlb_mod很怪,但是这里将文件系统服务进程放在用户态就很合理。在用户态,文件系统方便地对不同用户发出的请求进行调度,并进行磁盘驱动。
大抵是因为和磁盘的调用相比,进程间通信的开销是算小的。
在每个用户进程中,不同外设提供了统一的用户接口。
对于每个外设,有自己对于接口的实现,进一步要么通过自己用户空间进行访问,要么通过和fs(file system)进行通信。
fs进程包括首先对请求的分发、对于每个请求对应的有几个接口,在映射到磁盘块的具体实现。用到内存作为磁盘的cache的思想,先去内存固定的位置来找有没有,没有就通过磁盘驱动,进入内核访问磁盘。
IDE:Integrated Drive Electronics集成驱动器电子设备,是硬盘接口。
外设驱动的思想体现了层次化设计和上层的抽象和封装。提供统一的接口。
文件系统结构。mos中,fs目录下存放的是fs进程的代码,user/lib中的是文件系统的用户库。
文件对应一个数据结构,引入了文件描述符等结构。
三个目录:tools,fs,user/lib
MOS将进程页表映射到了fs进程,内核仅提供对设备物理地址的读写操作的系统调用
简单分析一下
一般的用户进程,有了访问文件的接口,从用户的角度来看,就是文件可写了,可读了。
fs这个用户进程,是一个有专门功能的进程,一方面需要进行通信,这里就涉及对用户进程请求的调度(比如一个很有意思的,linux的mv指令,对于在用一个文件系统的会直接改个映射,非常快,但是不同文件系统,就会先复制然后删除之前的。这个就是有fs进程进行判断并处理的),另一方面有硬件驱动,能够通过内核进行外设读写。
IDE磁盘驱动
- 不同的硬件设备有不同的操作方式和信号接口。操作系统需要通过设备驱动程序来翻译和传递这些特定的命令和信号,使得系统可以正常地使用这些硬件设备。
不太懂这些特定的命令和信号是什么意思
mips存储器地址映射,几乎每一种外设都是通过读写设备上的寄存器来进行数据通信。外设寄存器也称为I/O端口,主要用来访问I/O设备。外设寄存器通常包括控制寄存器、状态寄存器和数据寄存器,这些寄存器被映射到指定的物理地址空间。
实验中的mips体系结构没有复杂的I/O端口的概念,使用统一的内存映射I/O模型。在mips的内核地址空间实现了硬件级别的物理地址和内核虚拟地址的转换机制。
但是在这里使用qemu模拟操作系统,I/O设备的物理地址是完全固定的,可以通过简单的读写某些固定的内核虚拟地址来完成驱动程序的功能。
关于这里为什么使用kseg1这一个进行存取不会经过cache的地址空间,来作为使用Memory-Mapped I/O技术来访问的,我觉得应该是外设要求不经过外设于是产生了这一段地址空间。
作为相互印证的有,内核一般是不使用kseg1的,会将内核的.text .data .bss这些段放到kseg0中,同时bootloader好像也是运行在kseg1的,是因为bootloader需要完成很多初始化的工作,其中就包括对cache的初始化。因此也需要一块不经过cache的地址空间。
这么说来,似乎什么操作系统都得有这么一个类似的不经过cache的地址空间。
但从linux来说,在x86架构下是没有这个的,但是linux有一套mmap的api,可以设置禁用缓存的策略。同时x86用的是DMA直接对内存进行和其他设备的内存访问。
嘶,这里写思考题的时候我也纳闷了
guide-book 48页说运行在kseg1中的bootloader在载入内核前会进行cache的初始化
但是我翻了翻王道,搜了搜,又说会硬件自动完成初始化。
这里我的评价是,不同硬件条件不一样,运行在不同硬件架构的boot也不一样
MALTA的console设备是一个典型的NS16550设备。MALTA 开发板上的 console 设备确实是基于 NS16550 UART(Universal Asynchronous Receiver/Transmitter,通用异步收发器)的。NS16550 是一种非常经典的 UART 接口设备,被广泛应用在计算机系统中,用以提供串行通信。
其基地址是ox1800_03F8。只需要在0x1800_03F8 + 0xA000_0000这个地址写入字符就可以在控制台看到相应的输出。这里都已经牵涉到写入了,已经是在内核态了(printk,助教特意把这个名字改成了kernel)。
本次需要编写的IDE磁盘驱动程序位于用户空间,需要先经过系统调用进入内核。
那就在注册两个呗。sys_wrtie_dev sys_read_dev
这两个是为了在内核空间完成I/O操作。
有傻子
我还找了半天
过了好久好久,终于又开始写os了,这就是饥饿现象吗
- 扇区sector:圆环的一个片段
- 磁道track:不同半径的同心圆
- 柱面cylinder:不同盘片相同半径的磁道所组成的圆柱面
- 磁头head:每个磁盘有两个面,当对磁盘进行读写操作是,磁盘在盘片上快速移动
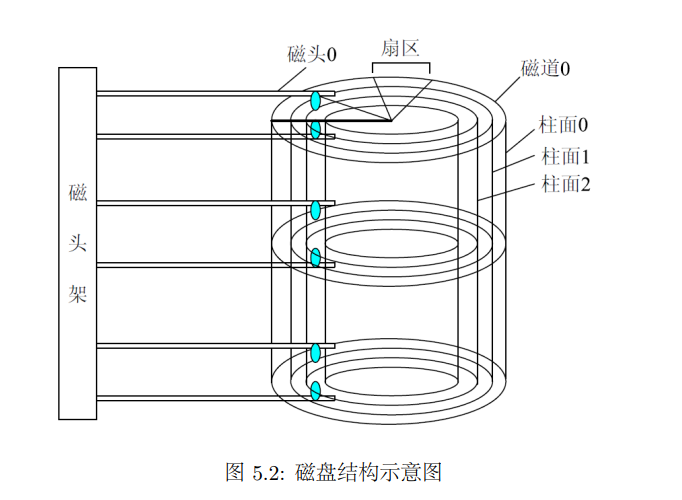
对于磁盘寻址,可以按照柱面-磁头-扇区(Cylinder-Head-Sector, CHS)的方式来定位一个扇区。
PIIX4 I/O的具体方式还是不一样。MALTA平台上的PIIX4磁盘控制器基地址为0x180001F0,与I/O相关的寄存器相对与改地址的偏移和对应的功能如下表所示。
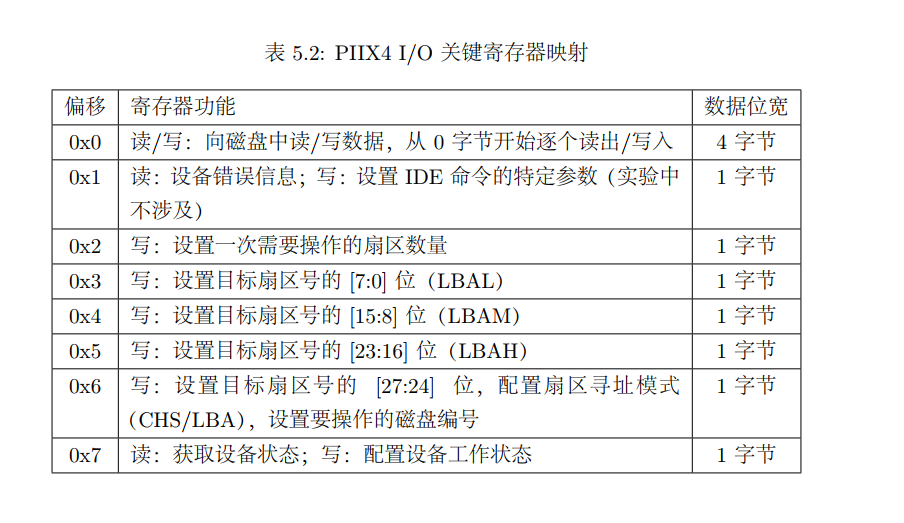
这里实际上就对应了我们鞥能够对外设进行的操作,而这个接口是有PIIX4来提供的。
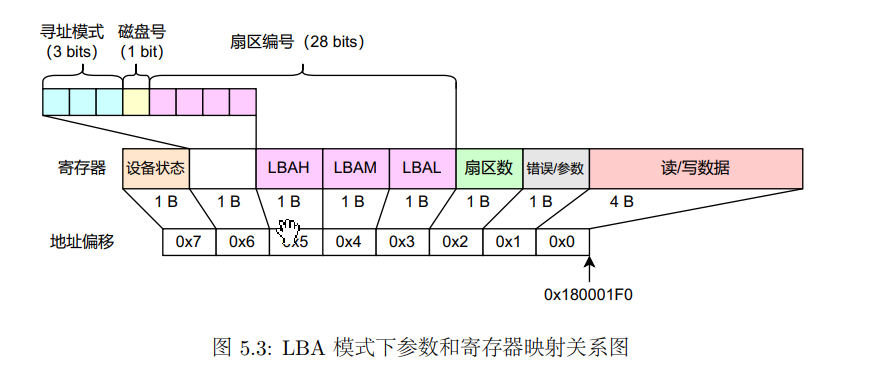
通过这个可以看到扇区有28位,也就是我们最多可以寻址$2^{28}$个扇区,而每个扇区的大小是512B,因此可以访问$128GB$的磁盘空间。
- 驱动程序编写
当需要从磁盘的指定位置读取或者写入一个扇区是,需要调用read_sector函数将磁盘中对应扇区的数据读到磁盘缓冲区中,
或者使用write_sector函数来缓冲区中的数据写入磁盘。
注意,与串口通信相同,这里所有的地址操作,都需要从物理地址转换成虚拟地址
but why?留个坑
在磁盘读写的流程中,需要反复检查IDE设备是否已经就绪。这是由于IDE外设一般不能立即完成数据操作,需要CPU检查IDE状态,并等待操作完成。
这里用到了我们不希望用到的轮询,但我们主要考虑的是实现的角度,具体性能问题不是我们关注的重点
这里构建了一个检查IDE状态的函数wait_ide,用于等待IDE上的操作就绪
在IDE设备就绪后,我们就可以对其进行读写操作了。
-
设置操作扇区的数目,这里只操作一个扇区,因此设置为1
这个应该就是随便操作操作?或者设置的是按照一个扇区一个扇区的访问?
-
一次设置操作扇区号,一次设置刚刚出现的那几个在基地址偏移上的寄存器。

因此这里还需要扇区殉职模式和磁盘编号。具体实现就是通过位运算将各值组合,并一齐写入对应地址。
-
完成一系列设置后,再次等待
IDE设备准备就绪,并在此之后,通过系统调用读取或写入扇区,即连续向相同的地址读取或写入4字节 -
最后,检查
IDE设备状态,确认扇区读取和写入成功
等等,刚刚那些都是在内核状态下的?那我们的微内核呢
原来得模仿上面的通过系统调用完成fs/ide.c中的相应函数,实现用户态对与磁盘的读写操作,注意这里的fs进程也是用户态下的一个进程。
只是用户进程与fs进程之间涉及到通信,必然需要进行系统调用进行ipc,进程间通信,来共享数据等。
文件系统结构
这一部分从内容上讲感觉比较简单,主要包括磁盘文件系统和文件结构体和块缓存三个部分。
磁盘文件系统指的是在磁盘文件中,如何组织各个文件。
- 从文件结构上面来讲,是块状串联的结构
- Block0是引导区
- Block1时超级块
- 接下来几个块是位图,用来标志各个数据块的使用情况。
使用一组枚举变量标志了每个块的用处
enum {
BLOCK_FREE = 0,
BLOCK_BOOT = 1,
BLOCK_BMAP = 2,
BLOCK_SUPER = 3,
BLOCK_DATA = 4,
BLOCK_FILE = 5,
BLOCK_INDEX = 6,
};总感觉这个不只是这点作用
关于blockno为0的问题,blockno=0说明是在引导区,所以这一块地方必然是不能被释放的。
有一句话非常精髓:文件系统需要负责维护磁盘块的申请和释放
对于每个文件(万物皆文件,把目录视为一种特殊的文件),如何进行管理呢
其中最关键的还是数据结构的考虑。
struct File {
char f_name[MAXNAMELEN]; // filename 文件名称,最大长度为128
uint32_t f_size; // file size in bytes 文件的大小,单位为字节
uint32_t f_type; // file type 文件类型,有普通文件FTYPE_REG和目录FTYPE_DIR两种
uint32_t f_direct[NDIRECT]; // 文件的直接指针,每个文件控制块有10个直接指针,用来记录文件的数据块在磁盘上的位置
// 每个磁盘块的大小为4KB,也就是这10个直接指针能够表示最大40KB的文件
uint32_t f_indirect; // 文件大于40KB时,需要用到间接指针。
// ((int*)(disk[dirf->f_indirect].data))[i]
struct File* f_dir; // the pointer to the dir where this file is in, valid only in memory.指向文件所属的文件目录
char f_pad[FILE_STRUCT_SIZE - MAXNAMELEN - (3 + NDIRECT) * 4 - sizeof(void*)];
// 是为了让整数个文件结构体占用一个磁盘块,填充结构体中剩下的字节
} __attribute__((aligned(4), packed));注释写得比较清楚了。这里关键需要思考的是f_indirect这个间接指针。
其实,这个指向了磁盘中的某一个块,直接去取即可。
具体部分可以循file_create的迹。
关于free_block
我的是
if (blockno == 0 || blockno >= super->s_nblocks) {
return;
}学长的是
if(blockno==0||(super!=NULL&&blockno>=super->s_nblocks)){
return;
}显然学长的更加合理。(虽然没必要,但是要知道C语言是一个容易内存泄漏的东东,这波我站学长!
实验体会
文件系统加上微内核结构整体还是非常好玩的。
但是在上机过程遇到一个神奇的bug,特地来补充一下实验报告。
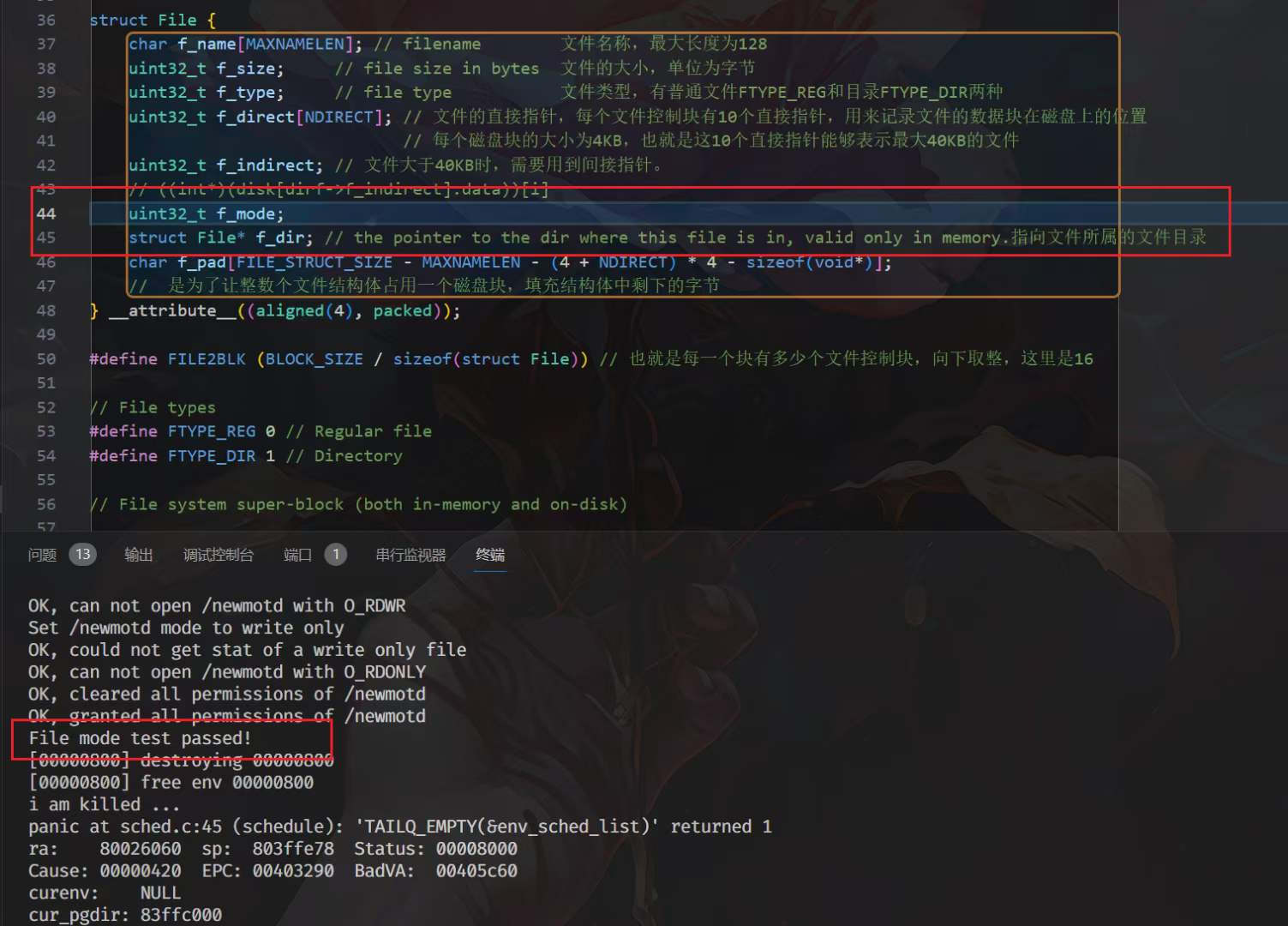
在反复寻找之后,发现bug出现在struct File里面
区别详见P1,P2
这里的区别在于我的f_mode放在一个void*的前面或者后面
但是在与给文件写入f_mode的时候是在x86这个64位机器上,void*是8个字节
而读的时候是在qemu模拟的32位mips这个机器上,void*是4个字节
那么就相当于读的时候是我写的时候的f_dir那个void*的后面4个字节,那不就是0了嘛
对于这种要在两个架构上面使用的结构体,还是按照P3的写法吧