[toc]
Lab6实验报告
思考题
Thinking 6.1
示例代码中,父进程操作管道的写端,子进程操作管道的读端。如果现在想让父进程作为“读者”,代码应当如何修改?
将case和default后面的内容交换即可。
#include <stdlib.h>
#include <unistd.h>
int fildes[2];
char buf[100];
int status;
int main()
{
status = pipe(fildes);
if (status == -1) {
printf("error\n");
}
switch (fork()) {
case -1:
break;
case 0: /*子进程-作为管道的写者*/
close(fildes[0]); /*关闭不用的读端*/
write(fildes[1], "Hello world\n", 12); /*向管道中写数据*/
close(fildes[1]); /*写入结束关闭写端*/
exit(EXIT_SUCCESS);
default: /*父进程-作为管道的读者*/
close(fildes[1]); /*关闭不用的写端*/
read(fildes[0], buf, 100); /*从管道中读数据*/
printf("father-process read:%s\n", buf); /*打印读到的数据*/
close(fildes[0]); /*读取结束,关闭读端*/
exit(EXIT_SUCCESS);
}
}Thinking 6.2
上面这种不同步修改 pp_ref 而导致的进程竞争问题在 user/lib/fd.c 中的 dup 函数中也存在。请结合代码模仿上述情景,分析一下我们的 dup 函数中为什么会出现预想之外的情况?
dup函数简单来说就是把一个文件描述块oldfdnum复制到newfdnum,可以看到dup函数中也是先映射文件描述块,然后映射具体的文件描述块的内容,对于一个匿名管道,文件描述块的内容就是pipe所在的数据块。
这里也是做了先映射文件描述块,然后映射pipe的操作,那么如果在中间发生进程切换,也就是考虑下面这个过程
pipe(p);
if (fork() == 0) {
read(p[0], buf, sizeof(buf));
} else {
dup(p[0], newfd);
write(p[1], "Hello", 5);
}考虑如果运行过程
- 父进程
dup函数中完成了newfd对p[0]的映射,那么pageref(p[0]) = 2 - 子进程继续进行
read,但是发现pageref(p[0]) == pageref(pipe) == 2 - 那么子进程就会认为写进程已经结束,同时此时
p->p_rpos == p->p_wpos,那么子进程的read就会直接结束 - 此时父进程的写进程永远无法结束,寄!
总而言之,就是dup函数可能在运行中间改变文件描述符的引用次数导致出现不可预料的问题。
Thinking 6.3
阅读上述材料并思考:为什么系统调用一定是原子操作呢?如果你觉得不是所有的系统调用都是原子操作,请给出反例。希望能结合相关代码进行分析说明。
有几个前提,
- 我们的内核只有一个进程一个线程
- 在进入系统调用syscall之前,
unset IE to globally disable interrupts
也就是在进行系统调用前关闭了中断,不会出现在syscall中再次出现系统调用的情况,因此可以确定在我们的MOS系统中系统调用一定是原子操作。
。。。
但是只要我把那一行删掉就可以不是了(x
Thinking 6.4
仔细阅读上面这段话,并思考下列问题
- 按照上述说法控制 pipe_close 中 fd 和 pipe unmap 的顺序,是否可以解决上述场景的进程竞争问题?给出你的分析过程。
- 我们只分析了 close 时的情形,在 fd.c 中有一个 dup 函数,用于复制文件描述符。试想,如果要复制的文件描述符指向一个管道,那么是否会出现与 close 类似的问题?请模仿上述材料写写你的理解
可以解决上述场景的进程竞争问题。
这里考虑的完全是pageref
显然有pageref(pipe) >= pageref(fd),而先取消pipe的映射,可能导致应该是pageref(pipe)>pageref(fd)变成pageref(pipe)==pageref(fd),但是先取消fd的映射就不可能出现这个情况,因此不会误判另一端已经关闭。
可能出现上述问题,在6.3已经提到了原因。
dup函数也会出现与close类似的问题,也就是可能因为先进行fd的pageref添加导致出现pageref(pipe)==pageref(fd),因此先增加pageref(pipe)就不会出现这种情况,这里事实上是认为过程中任何一个时刻都不能出现满足那个情况的时候,因为很有可能会出现在那个时刻的前一时刻进行进程切换导致出现问题的情况。
Thinking 6.5
思考以下三个问题。
认真回看 Lab5 文件系统相关代码,弄清打开文件的过程。
回顾 Lab1 与 Lab3,思考如何读取并加载 ELF 文件。
在 Lab1 中我们介绍了 data text bss 段及它们的含义, data 段存放初始化过的全局变量, bss 段存放未初始化的全局变量。关于 memsize 和 filesize ,我们在 Note1.3.4中也解释了它们的含义与特点。关于 Note 1.3.4,注意其中关于“bss 段并不在文件中占数据”表述的含义。回顾 Lab3 并思考: elf_load_seg() 和 load_icode_mapper()函数是如何确保加载 ELF 文件时, bss 段数据被正确加载进虚拟内存空间。 bss 段在 ELF 中并不占空间,但 ELF 加载进内存后, bss 段的数据占据了空间,并且初始值都是 0。请回顾 elf_load_seg() 和 load_icode_mapper() 的实现,思考这一点是如何实现的?
下面给出一些对于上述问题的提示,以便大家更好地把握加载内核进程和加载用户进程的区别与联系,类比完成 spawn 函数。
关于第一个问题,在 Lab3 中我们创建进程,并且通过 ENV_CREATE(…) 在内核态加载了初始进程,而我们的 spawn 函数则是通过和文件系统交互,取得文件描述块,进而找到 ELF 在“硬盘”中的位置,进而读取。
关于第二个问题,各位已经在 Lab3 中填写了 load_icode 函数,实现了 ELF 可执行文件中读取数据并加载到内存空间,其中通过调用 elf_load_seg 函数来加载各个程序段。在 Lab3 中我们要填写 load_icode_mapper 回调函数,在内核态下加载 ELF 数据到内存空间;相应地,在 Lab6 中 spawn 函数也需要在用户态下使用系统调用为 ELF 数据分配空间。
- 用户打开文件为调用
open()函数,然后调用fdipc_open()给文件服务进程发消息,文件服务进程接收到消息后调用serve_open()函数,然后创建文件,打开文件,将FileFd传递回去 - 读取ELF文件,只需要知道结构体
struct Elf32_Ehdr的结构,然后依次读取段头表和节头表即可。加载ELF文件在kern/env.c中的load_icode中进行了实现,实际上其中的关键部分还是lib/elfloader.c中的elf_from函数 - 在
elf_load_seg()中,如果bin_size < sgsize时那么,调用回调函数elf_mapper_t即可,这里的回调函数也就是load_icode_mapper(),在这个函数中,会再次进行page_insert也就是保证申请足够的地址空间来存放bss区域,同时通过设置src = NULL即可得到设置初始值为0.
乐,才发现后面有提示
Thinking 6.6
通过阅读代码空白段的注释我们知道,将标准输入或输出定向到文件,需要我们将其 dup 到 0 或 1 号文件描述符(fd)。那么问题来了:在哪步, 0 和 1 被“安排”为标准输入和标准输出?请分析代码执行流程,给出答案。
在user/init.c中
// stdin should be 0, because no file descriptors are open yet
if ((r = opencons()) != 0) {
user_panic("opencons: %d", r);
}
// stdout
if ((r = dup(0, 1)) < 0) {
user_panic("dup: %d", r);
}这里设置了文件描述符为0则为标准输入,因为此时没有打开任何文件描述符然后在进行复制的时候设置了1为标准输出。
Thinking 6.7
在 shell 中执行的命令分为内置命令和外部命令。在执行内置命令时 shell 不需要 fork 一个子 shell,如 Linux 系统中的 cd 命令。在执行外部命令时 shell 需要 fork一个子 shell,然后子 shell 去执行这条命令。
据此判断,在 MOS 中我们用到的 shell 命令是内置命令还是外部命令?请思考为什么Linux 的 cd 命令是内部命令而不是外部命令?
内置命令是shell程序自己的功能,直接执行,不需要创建新的进程;外部命令则是磁盘上的程序,需要创建新的进程来执行。
我们在MOS中用到的shell命令时外部命令,在sh.c中可以看到
最关键的部分是启动shell后的循环中的部分:
if (interactive) {
printf("\n$ ");
}
readline(buf, sizeof buf);
if (buf[0] == '#') {
continue;
}
if (echocmds) {
printf("# %s\n", buf);
}
if ((r = fork()) < 0) {
user_panic("fork: %d", r);
}
if (r == 0) {
runcmd(buf);
exit();
} else {
wait(r);
}也就是都是fork()了一个子进程来执行,因此这是一个外部命令。
cd用来改变当前的工作目录。如果cd是一个外部命令(也就是在子shell中运行),那么它会在子shell中改变目录,然后子shell执行完毕,父shell的工作目录并未改变。这显然是无效的,所以cd必须是内置命令,在当前shell中直接执行,以改变当前shell的工作目录。同时这样还能减少开销。
Thinking 6.8
在你的 shell 中输入命令 ls.b | cat.b > motd。
- 请问你可以在你的 shell 中观察到几次 spawn ?分别对应哪个进程?
- 请问你可以在你的 shell 中观察到几次进程销毁?分别对应哪个进程?
得到输出:
[00002803] pipecreate
[00003805] destroying 00003805
[00003805] free env 00003805
i am killed ...
[00004006] destroying 00004006
[00004006] free env 00004006
i am killed ...
[00003004] destroying 00003004
[00003004] free env 00003004
i am killed ...
[00002803] destroying 00002803
[00002803] free env 00002803
i am killed ... 在spawn.c中添加
debugf("spawn: father %x, child %x\n", syscall_getenvid(), child);重新执行得到结果:
[00002803] pipecreate
spawn: father 2803, child 3805
spawn: father 3004, child 4006
[00003805] destroying 00003805
[00003805] free env 00003805
i am killed ...
[00004006] destroying 00004006
[00004006] free env 00004006
i am killed ...
[00003004] destroying 00003004
[00003004] free env 00003004
i am killed ...
[00002803] destroying 00002803
[00002803] free env 00002803
i am killed ...可以看到调用了两次spawn,分别是进程2803生成了3805,和进程3004生成了4006。
spawn的作用是loading executable code to memory,也就是在需要加载可执行文件时会调用这个。
同时可以看到出现了四次进程销毁:
其中进程号为2803的进程应该是ls.b | cat > motd 这一行代表的shell子进程
其中进程号为3805的进程应该是ls.b,这个进程是由2803首先spawn生成的,因此应该是首先调用的ls.b
其中进程号为3004的进程应该是cat.b > motd这一个管道右边的指令,当shell遇到管道时,会在这里再次fork一个进程,也就是2803的子进程3004
其中进程号为4006的进程应该是cat.b,这是3004在执行是调用加载二进制文件时需要用到的。
难点分析
关于管道
-
实验目的
pipe
shell
shell中设计pipe“|”的部分
-
管道
是进程间通信的另一种方式,显然是进程间单向通信的一种方式。
mos中pipe的使用与实现
首先分析Pipe这个结构体
struct Pipe {
u_int p_rpos; // read position,下一个将要从管道读的数据的位置
// 只有读者可以更新 p_rpos
u_int p_wpos; // write position,下一个将要向管道写的数据的位置
// 只有写者可以更新 p_wpos
u_char p_buf[PIPE_SIZE]; // data buffer
// 这个 PIPE_SIZE 大小的缓冲区发挥的作用类似于环形缓冲区
// 所以下一个要读或写的位置 i 实际上是 i%PIPE_SIZE
// 所以如果管道数据为空,即当 p_rpos >= p_wpos 时,应该进程切换到写者运行
};这里就要分析管道的特殊作用。管道是一种只存在于内存中的文件(与磁盘中的文件啥的相对,linux一切皆文件)。这里会同步进行读和写,那么如何做到这一个呢,首先由于不希望进行通信,那么实际上会有同一块内存区域,然后为了考虑同步读和同步写,需要在内存区域中添加读和写的一个指针。
所以如果管道数据为空,即当 p_rpos >= p_wpos 时,应该进程切换到写者运行。
同时写者在写入的时候,也是将数据存入缓冲区,需要注意管道的缓冲区可能出现满溢的情况,所以写者必须得在p_wpos-p_rpos < PIPE_SIZE时方可运行,否则要一直挂起。
同时为了解决部分死锁的问题,需要知道管道的另一端是否已经关闭,当出现缓冲区为空或满的情况是,要根据另一端是否关闭来判断是否要返回。如果另一端已经关闭,进程返回0即可;如果没有关闭,则切换进程运行。
然后分析一下pipe函数的具体实现。父子进程的p[0] 和 p[1]访问到的内存区域应该是一致的。
那么在pipe中是如何实现的呢,
首先通过fd_alloc和syscall_mem_alloc两个函数分别创建文件描述符并为文件描述符分配空间
然后给fd0对应的虚拟地址分配一页物理内存,再将fd1对应的虚拟地址映射到这一页物理内存。
注意这里创建文件描述符fd0 fd1和为文件描述符对应的虚拟地址分配物理空间时用到的权限位都是PTE_D|PTE_LIBRARY,PTE_D可以理解,表示可写,PTE_LIBRARY实际上还表达了父子进程可以对这个共享页面直接进行写操作,也就是共享可写页面!
这里讲一下为什么先要分配这三个物理页面
这里需要分析一下
fd_alloc的实现,这里的关键实际上是*fd = (struct Fd*)va;也就是说只是找到了一个没有使用过的虚拟地址,但是如果需要使用这个物理地址,是需要对应到实际的物理页面的。同时
fd也需要对应到实际的物理页面。那么这里就需要创建三个页面了。
在MOS中,使用了_pipe_is_closed()来判断管道的另一端是否已经关闭。
这个是如何实现的呢,又是什么原理呢。
确定几点,管道只有一端读一端写,每一个匿名管道分配了三夜空间,一页是读数据的文件描述符fd0,一页是写数据的文件描述符fd1,同时还有一页被两个文件描述符共享的管道数据缓冲区pipe。
那么显然有pageref(rfd)+pageref(wfd)=pageref(pipe)成立。
那么要判断另一端是否已经关闭实际上是判断另一端的pageref是否为0,那么实际上就是判断pageref(fd) == pageref(pipe)是否成立。
内核会对
pages数组成员维护一个页引用变量pp_ref来记录指向该物理页的虚页数量。
看看pipe_close这个函数
这里进行了两个syscall_mem_unmap的操作
目前的
unmap的顺序是,先取消对
pipe的映射,然后再取消对文件描述符的映射
在这个情况下我们考虑
pipe(p);
if (fork() == 0) {
close(p[1]);
read(p[0], buf, sizeof(buf));
} else {
close(p[0]);
write(p[1], "Hello", 5);
}如果执行顺序是
-
子进程
close(p[1]); -
父进程
close(p[0]);仅完成了取消p[0]对pipe的映射此时每个页面的引用情况为:
pageref(p[1]) = 1;
pageref(p[0]) = 2;
pageref(pipe) = 2;
-
子进程执行read,判断写端已经关闭,因为
pageref(p[0]) == pageref(pipe),相当于认为pageref(p[1]) == 0因此斗胆猜测,如果判断写端关闭的时候把两个都加上是不是就没问题了(x
那么此时
rbuf = (char*)vbuf; for (int i = 0; i < n; i++) { while (p->p_rpos == p->p_wpos) { if (_pipe_is_closed(fd, p) || i > 0) return i; syscall_yield(); } rbuf[i] = p->p_buf[p->p_rpos % PIPE_SIZE]; p->p_rpos++; }那么此时就会发现
p->p_rpos == p->p_wpos但是写端没有关闭,因此就会进行系统调用,然后父进程继续完成进行,搞定!
这里还解释一下把两个unmap的顺序调整后可行的原因。
这里考虑的完全是pageref
显然有pageref(pipe) >= pageref(fd),而先取消pipe的映射,可能导致应该是pageref(pipe)>pageref(fd)变成pageref(pipe)==pageref(fd),但是先取消fd的映射就不可能出现这个情况,因此不会误判另一端已经关闭。
然后就是读的时候也可能因为进程切换出现问题,这里好办,只要判断没有进行进程切换即可,也就是这个过程前后没有发生进程切换,那么用一个全局变量来判断即可,也就是env_runs,记录了某个进程run的次数
关于shell
shell的启动
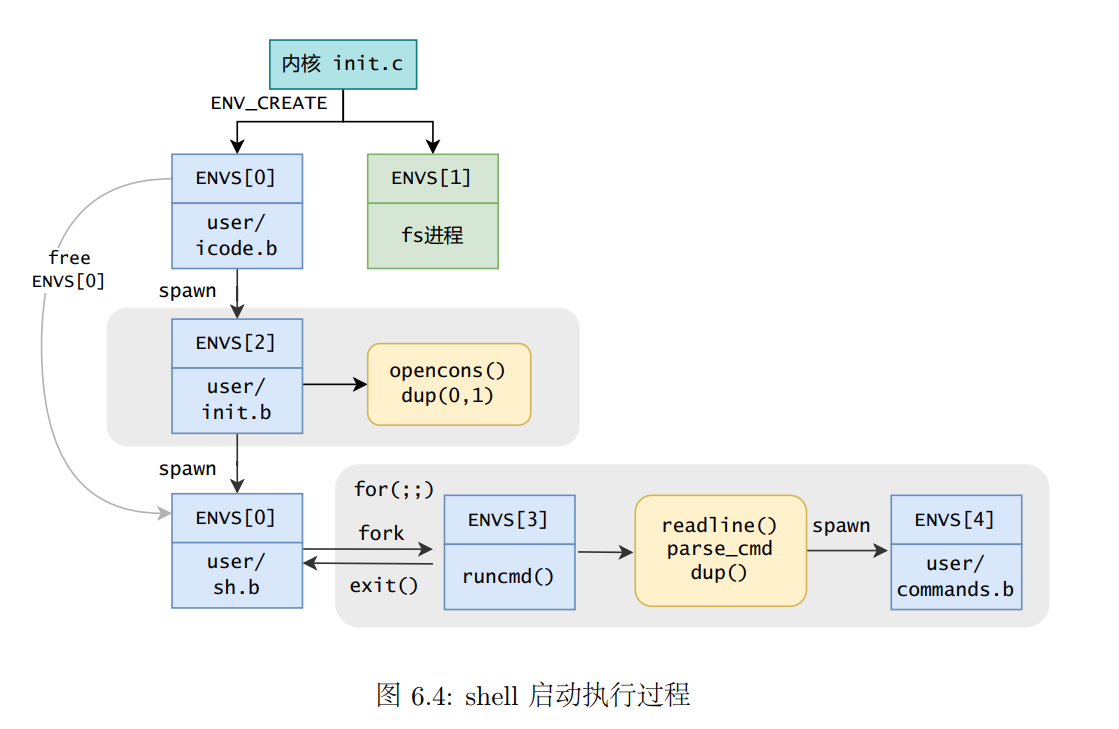
shell相关的函数调用关系
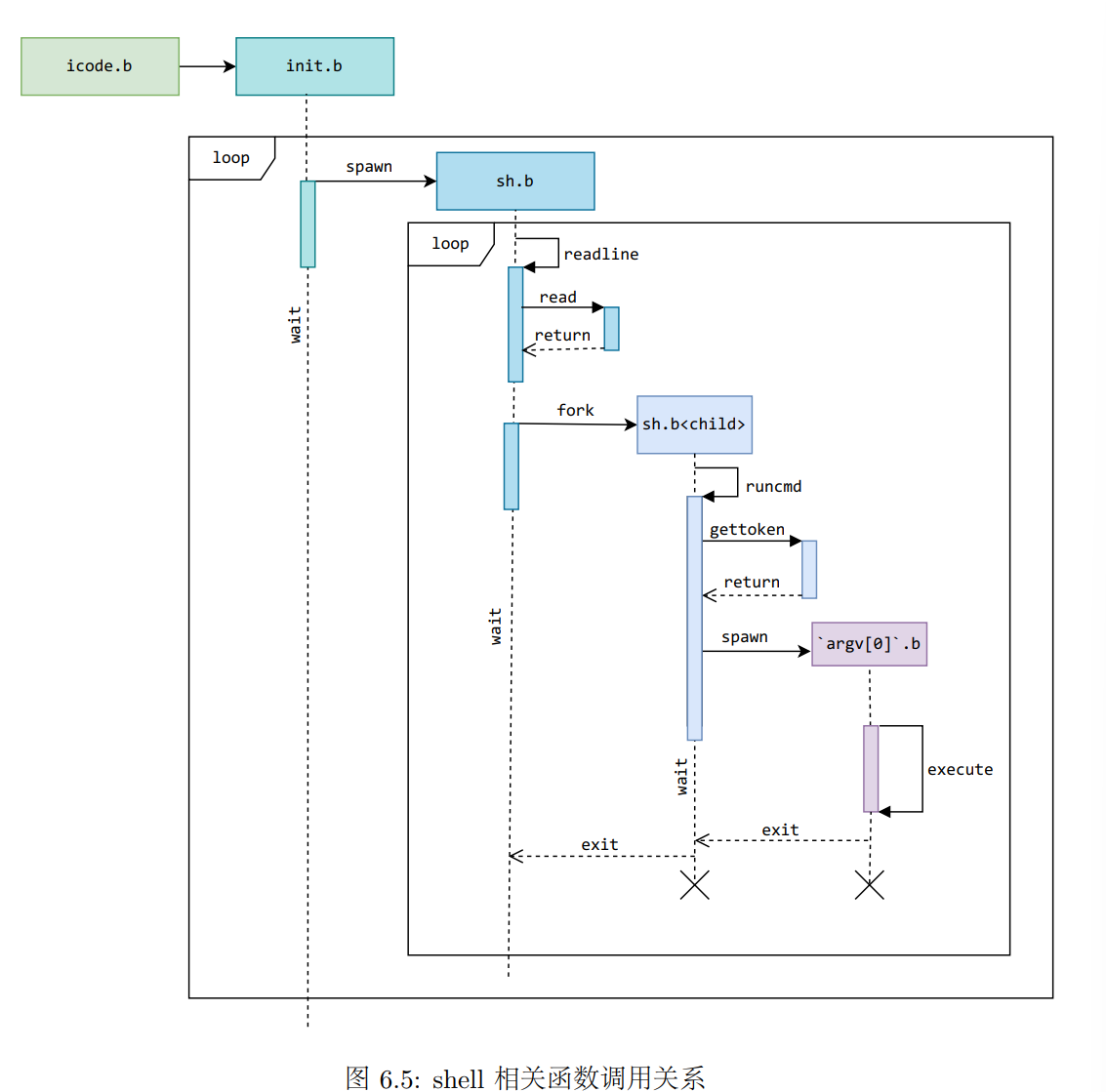
我觉得这两个流程都是很关键的,关键在于可能在哪里进行fork了一个子进程就会得到差别很大的结果。

实验体会
finally,终于到了最后一个lab了,虽然这个lab我还需要上机,我还是非常喜欢的。
整体os体验下来,我觉得大概是两个字:享受。
指导书非常的清晰,代码架构非常的好看,可能上机对我比较残酷,但是我觉得这并不影响我喜欢os这门课程。
希望上机顺利,之后也会继续把shell做好!
操作系统,心向往之~

